Table of Contents
gvnn=Geometric Vision NN(2016)
citation > 44
Abstract:
幾何学的コンピュータビジョンをDNN on Torchで実現。
Spatial Transformer Networkに続いて、パラメトリックな変換を実現する新しいレイヤ群を提案。
これらの層は、元々空間変換器の気持ちで追加されたが、バックプロパゲーションにより、Geometric Computer Visionのドメイン知識をEtE学習できるようになった。
本論文により次のような応用への道が切り開かれた:
- 位置認識
- カメラ自体の回転と平行移動(odmetry)
- depth(深度)推定
- パラメトリック変換による歪みから画像を再構成する教師なし学習
Reweighted Random Walks for Graph Matching(2010)
Link: https://link.springer.com/content/pdf/10.1007%2F978-3-642-15555-0_36.pdf
2枚の画像の同一物体(が違う角度で置かれている場合)をマッチングさせる問題を、特徴点グラフのマッチング問題と捉えることができる。これは、行列表現を使えばIQP(Integer Quadratic Problem)と等価になる。
これはレイリー商をx∈整数定数長ベクトルで最大化する問題だからである。
 \sim R(\bold{W}, \bold{x})")
IQPはNP-Hardなので、近似解法が欲しい。境界条件を無視すれば、Markov過程としてモデリングすることができる。これをRWGM(Random Walk on Graph Matching)と呼ぶ。
しかしここに罠があって、この問題はMarkov過程では解けないのである。ここを正しく理解しておくことが重要。
行列表現を取った場合、Wの値の大きなものには、偽陽性が含まれるのである。これは、FOS(First Order Similarity. パッチの類似性)から行列Wを作ってしまったからである。だから、Wを使ってMarkov過程を作ると、その偽陽性が邪魔して真の解には収束しない。(FOS自体は真実の値なので、FOSが悪いわけではないことに注意)
ゆえに、RWGMにはabsorbing nodeがあるのだ。
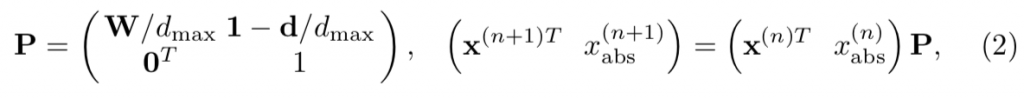
境界条件は陽に取り扱わず、Reweight / jumpという概念の導入で、適当にlocal minimaから脱出させる過程をいれて、ハイパーパラメーターを増やす方向で解決可能である。これが表題のReweighted-RWGMである。

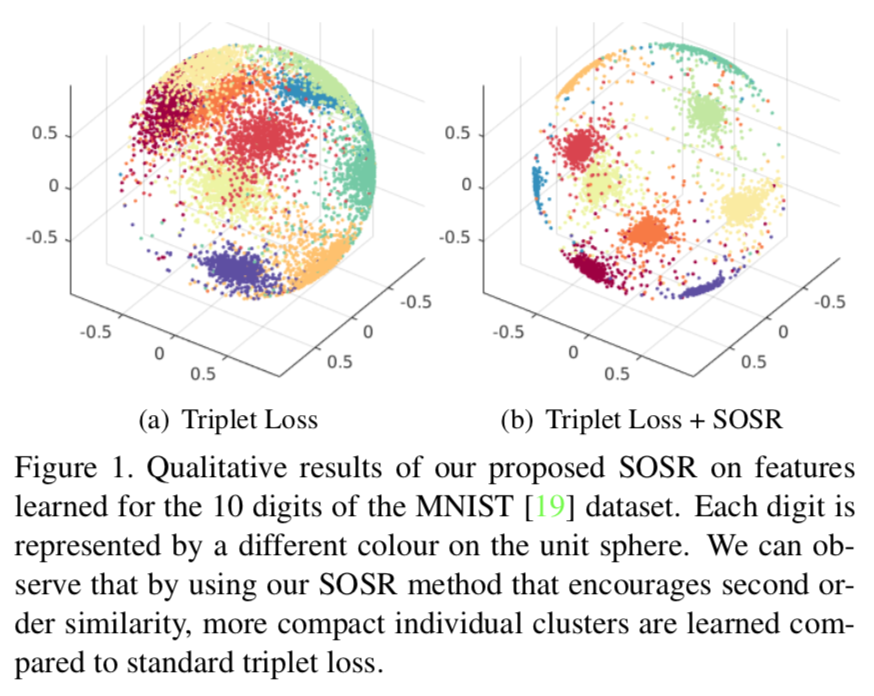
この方法はSOS(Second Order Similarity)と呼ぶ。イメージパッチ同士の距離を評価するのがFOS(First Order Similarity)であるが、この方法は、イメージパッチを頂点とするグラフのエッジv_ijに着目し、v_ijを頂点とするグラフ(Second Order)上でのRandom Walkを考えるからである。
この9年後、SOSマッチによってEmbedding空間での局在性/分離性が高まることが2019年に証明された。
LEARNING TO EXECUTE(2014)
概要
数式の計算や、プログラムを実行を行えるuni-directional(一方向の)多層LSTMである。実際、数式の計算は、”print(12+35)”のように、プログラムの一種として扱われている。
リンク
https://arxiv.org/abs/1410.4615
先行研究との比較
この研究では数式を、あえて意味を持たせない記号のSequenceとして扱っている。つまり、このニューラルネットワークは”1”が10個ある数字の1つであることも、”2>1”であることも知らない。また、繰り上がり(carry)などの概念も知らない。
このように、数式をパース済みツリーではなく文字列だと考えたタスク設定が面白い。さらに、このようにSequenceを入力にしてもnest式が動くという事実の発見が面白い。例えば、((1+2)*4)/3=4であるが、()が2重になっていることから、その取り扱いは複雑になるわけだ。
技術や手法のキモ
まず、学習データが無限にプログラムで生成できる点が面白い。ここではプログラムを生成し、それに言語のeval()を適用することで答えを生成する。(luaで書かれている)
また、この問題は複雑すぎてSeq2Seqで学習すると失敗する確率が高い。そこで、補助輪として、
- input doubleing
= 数字を覚えるタスク(memorization task)において、142856;142856;から142856を生成させる - teacher forcing
= N+1桁目を予測させる際に、1~N桁目まではSeq2Seqの出力ではなく真の値を差し替えて与える - curriculum learning(Bengio,2009)
= 簡単な問題で学習したpretrainedモデルで学習することを多段計画(カリキュラム)にしたがって行う
といった手法が追加されている。
物議
まず、生成されたデータセットが偏っているのは問題である。
((1+2)*4)+8=20
は生成されるが、
((1+2)*4)/8=1.5
は生成されない(割り算がないため)仕組みになっているわけだ。循環小数も当然表現されないので、フレームワーク自体が有限桁であるこのネットワークには無理であり、
((1+2)*4)/7=
には解がない。
次に、2重以上の()が動作するので見落とされがちだが、2重のforLoopは実はこのプログラムでは学習できない。また、alignmentに弱い。これは、1++や、001などが生成できてしまうことや、123+456のなかから「123が独立の単語である」ということを認識できないことを意味する。
また著者らは、「記憶の圧縮仮説」のようなものを提出している。その理由は、4桁の数字を学習(memorization task)させた後に5桁の数字を学習させることが可能で、その場合に4桁の数字の分散表現の体積が減っているからだ、としている。これには十分な根拠がなく、怪しいものである。
次に読むべき研究
この研究の延長線上に、積分と微分方程式を解くことのできる
DEEP LEARNING FOR SYMBOLIC MATHEMATICS (2019)
https://arxiv.org/abs/1912.01412
があるので、それを読むと良いと思う。
また、なぜこのSeq2Seqで積分や微分方程式が解けないのかを理解するには、Additive Attentionを学ぶ必要があるので、Bahdanauの
Neural Machine Translation by Jointly Learning to Align and Translate(2014)
(リンクはこのサイト上の解説)を読むのがいいと思う。また、LSTMがうまく学習できない場合について、同じ著者 らZaremba&Sutskever+Vinyalsの
Recurrent Neural Network Regularization(2014)
https://arxiv.org/abs/1409.2329
も読むといいらしい。
最後に、記憶の圧縮仮説についてそれらしい論文として、DeepMindの、
Compressive Transformers for Long-Range Sequence Modelling(2019)
https://arxiv.org/abs/1911.05507
をあげておきたい。(ICLRの査読中)
アブストの翻訳
LSTMを使ったRNNは、表現力があり、トレーニングが容易であるため、広く使われています。
コンピュータープログラムの評価(※品質評価のことではなく、実行して結果を得ることを評価という)はニューラルネットワークでは実現できないような複雑すぎるタスクだと見なされてきました。
我々はSeq2Seqを使ってそれを学習することに興味があります。
我々は単純なケースにフォーカスし、固定長メモリと単方向LSTMを使って学習します。
メインリザルトは、LSTMは文字レベルの表現で、入力から正しい出力へのマッピングを学習可能だということです。
特筆すべきは、カリキュラムラーニングが必要なことです。従来のカリキュラムラーニングは役に立ちませんが、今回のタスクに有効な亜種を開発しました。
これにより、99%の精度で2つの9桁の数値を足し算できるようになりました。
Sequence to sequence learning with neural networks(2014)
概要
SequenceをSequenceに変換(transduction)するuni-directional(一方向の)多層LSTM。
リンク
https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
先行研究との比較
この論文は、SMTにDNNが初勝利したという点で画期的であった。さらにこのSeq2Seqモデルはドメインによらず有効であると主張された。実際、私がみた限りでも、
- 翻訳
- 数式生成
をうまく解くことが出来ていた。(どのような問題が苦手かには後述のように実は条件があるのだが、論文の出版後1~2年間で判明していった)
従来の論文は音声の問題に特化したり、翻訳の問題に特化したネットワーク設計を行なっていたので、この論文の”Sequence to Sequence”という一般的な問題設定は素晴らしかった。
翻訳の問題では、言語による文法が異なるため、対応する単語同士の順序が入れ替わることもあるが、Seq2Seqモデルはこれを問題なく翻訳できる。この性質は”アラインメントに単調性を仮定しないで良い”と表現されていた。
技術や手法のキモ
short term dependencyという小手先の技法で、abcをcbaにreverseしてαβγを学習させる点がこの手法の肝である。
また、従来はCTC(Connectionist Temporal Classification)で全ての場合の数を探索して最も確率の高いシーケンスを返していたため、組み合わせ爆発が起きていた。その代替としてBeam Searchを採用した。Beam SearchはBeam(幅)をあらかじめ自然数定数値に設定し、その幅内のTop候補のみを保持する方法である。これによって高速化した。
CTCについてはSpeech Recognition with Deep RNN(2013)の解説を参考のこと。
物議
この論文の最後の主張はReversingによってshort-term dependencyが増えることによって、学習が容易になるというものだが、なぜうまくいくかの説明が不完全であると著者も認めている。
次に読むべき研究
Seq2Seqモデルの画期的だった点は、シーケンスの位置座標を、時間座標で代替したことだった。しかし、これが真に正しい方法でないことが、Additive Attentionによって後年明らかになってきた。
Additive Attentionを導入したBahdanauの論文Neural Machine Translation by Jointly Learning to Align and Translate(2014)を読むことをお勧めする。
アブストの翻訳
ディープニューラルネットワークは、ラベル付けされた大きなトレーニングセットから難しいタスクを学習できます。しかし今のところ、DNNを使用してシーケンスをシーケンスにマッピングすることはできません。
これはシーケンスの学習のための、汎用的なend2endアプローチです。汎用的とは、データのシーケンスの構造について最小限の仮定のみを行うことを意味します。
我々は多層Long Short-Term Memory(LSTM)を使用して入力シーケンスを固定次元のベクトルにencodeし、次に別の多層LSTMを使用してターゲットシーケンスへとdecodeします。
我々は、WMT-14 English to Frenchの翻訳タスクで、語彙外でペナルティを課される制約下で、34.8(BLEU)を達成しました。
さらに、LSTMは長文も扱えます。 フレーズベースSMTが33.3(BLEU)を達成するデータセットで比較すると、LSTMでReRankした場合36.5に増加します(=StateOfTheArt)。
LSTMは、単語の順序で意味が変わってしまうような句や表現を学習することもできました。また、受動態と能動態で意味が不変である句や表現も学習することができました。
最後に、ソース文の単語順を逆にし、ターゲット文の単語順をそのままにした場合、パフォーマンスが著しく向上することがわかりました。ソース文とターゲット文の間にshort-term dependencyが増し、最適化が容易になったためと考えられます。
Neural Machine Translation by Jointly Learning to Align and Translate (2014)
概要
Bahdanau(読み方は多分”バーダナ”)が作った、翻訳をうまく行えるNNである。
https://arxiv.org/abs/1409.0473
この手法は後年”Additional Attention”と呼ばれた。
先行研究との比較
翻訳の分野は、長らく「encoder-decoder」モデルが使われていた。
例として英語からフランス語への翻訳を考える。
encoderは入力された英語の文章を、連続値をとる有限次元ベクトルの空間に埋め込む。
decoderは連続値をとる有限次元ベクトル表現から、フランス語の文章を生成する。
この研究がenc-decモデルより優れているのは、有限次元ベクトルに長いセンテンスの全情報を格納(squash)しない、ということである。
技術や手法のキモ
①encode結果がベクトル系列になり、decoderはその中から使うものをα_ij(関係ある確率を表現する確率分布。エナジーe_ijのボルツマン分布)に従い選択する仕組み。これを、アラインメントと対比させて、ソフトアラインメントと読んでいる。
②Joint Training(Alignment + Translation)
検証方法
50単語の英語→フランス語の性能を評価した。
指標はBLEU 。
enc-decモデルはencoderへのinputサイズ(この論文では50)の半分を超える長さの文章を学習できないが、Additional Attentionの場合は50単語に近づいても性能が劣化しない。
物議
短い文→長い文の2段階のトレーニングをしているので、人の手が入っていると言えるのではないか(カリキュラムトレーニングっぽい)
この学習方法に改善の余地があるのでは?
また、ボルツマン分布を作るときにAdditionを行うこと自体には、必然性はなく、改良の余地があるらしい。
次に読むべき研究
Attention is All You Need
では、AdditionalではないAttentionの使い方をしているのでそちらを読んだほうがいい。
アブストの翻訳
ニューラルネットによる機械翻訳は、ごく最近のアプローチです。
従来の統計的機械翻訳とは異なり、このアプローチは単一のニューラルネットワークで翻訳パフォーマンスを最大化することを目的としています。
最近提案されたモデルは、多くの場合encoder-decoderモデルで、ソース文を固定長のベクトルにエンコードするencoderと、固定長のベクトルから翻訳を生成するdecoderで構成されます。
この論文では、固定長ベクトルの使用がパフォーマンスを低下させていると考え、モデルの一部をソフトに検索可能に拡張します。
この手法ではソース文の中のターゲットワードの予測に関連する部分を、明示的にハードセグメントとして形成する必要がありません。
この新しいアプローチは、英語からフランス語への翻訳において、SOTAを実現します。
さらに、定性分析により、モデルで見つかったソフトalignmentが直感とよく一致しすることがわかります。
Speech Recognition with Deep RNN(2013)
概要
GravesはLSTMをはじめとした研究で功績を残した人。この論文は彼の初期の名作で、会話(音素や言語、文法)を認識する双方向(bi-directional) LSTMだ。
共著者にMohamed/Hintonがいる。双方向の問題設定は、認識の全体感に問題意識をもつHintonらしい問題設定である。
https://arxiv.org/abs/1303.5778
先行研究との比較
以前から、時間座標を文章内部の位置座標の表現に使うRNNはポピュラーであった。
この論文は、LSTMが持っていた時間座標とDeepNeuralNetworkが持っていた空間座標を関連づけたところがすごい。
これは、双方向ネットワークを使った問題設定が優れているということと等価なので解説する。
著者らは、「音は聞き取り終わってから脳により分析が始まる」と考えており、文章においてN番目の要素は、文全体(文の任意の位置の要素)の影響を受けるとモデリングした。
論文には書いていないが、文章の生成側についても、「脳が全体を考えてから文章化している」とすると、N番目の要素が文全体から影響を受けると考えるのは理にかなっている。
こう考えると、先行研究のように、時間座標のように一方向な座標を使うのはおかしいことになる。
論文ではこれを”shortcoming”と表現している。
技術や手法のキモ
この分野ではConnectionist Temporal ClassificationでP(k| t)のみが求められていた。
つまり、音素のモデルと言語のモデルは別々に学習されていた。
これをJoint trainingにし、P(k|t, u)(同時条件付き確率)を求めるところが学習手法のキモである。
物議
わからない。
次に読むべき研究
時間座標を用いて大きな成功を抑えた
Seq2Seq
を読んでみてはどうだろうか。
問題特性に応じて、最適なモデルが変わる(ノーフリーランチ定理)ことが再確認できるはずである。
また、アラインメントがそもそも決定できないものという過程を置き、ソフトアラインメントを採用した、
Neural Machine Translation by Jointly Learning to Align and Translate (2014)
を読んでみるのもいいだろう。
アブストの翻訳
RNNはSequentialデータを扱うのが得意です。
Connectionist Temporal Classificationというend2endの学習方法を採用すると、入力と出力のalignment(推測だが、連続音なので、単語の区切りがどこかなどの情報)が不明なシーケンスをラベリングする問題を学習できます。
この学習方法とLong Short-term Memory RNNの組み合わせは、筆記体の手書き文字認識でSOTAです。
しかし、音声認識においては期待外れなことに、ディープフィードフォワードネットワークに負けています。
この論文では、Deep RNNを用い、非常に効果的であることが判明済みな複数レベルの表現と、長距離コンテキストの使用を組み合わせます。
適切な正則化のもとでend2endでトレーニングすると、TIMIT音素認識ベンチマークで17.7%のテストセットエラーを達成します。
引用数
2020/3/17 5267
Generating Sequences With Recurrent Neural Networks(2013)
概要
GravesはLSTMをはじめとした研究で功績を残した人。この論文は彼の初期の名作で、手書き文字を生成するunidirectional LSTMだ。
https://arxiv.org/abs/1308.0850
生成された絵を見れば如何に凄いかわかる。人間が書いたとしか思えないのだ。
技術や手法のキモ
まず、LSTMで点の(x, y)座標を1点ずつ生成していくところは2013年当時としては極めてユニークと言えるだろう。
また、Gravesという著者の論文全てに言えることだが、問題の定式化が極めて自然で洗練されている。この論文の場合は、手書き文字を、ガウス混合分布でモデリングしている。つまり、文字列を文字の重心集合の分布を潜在変数とする確率分布からのサンプリングと考えているわけだ。
物議
ただ、これほど高精度なこのモデルは音声や翻訳といったトランスダクション(trunsduction)には機能しない。
これは双方向(bi-directional)LSTMへの伏線で、同年のGraves & Hintonの論文で優雅に回収される。
次に読むべき論文
Speech Recognition with Deep RNN(2013)
アブストの翻訳
LSTMを使うと、一度に1つのデータポイントを予測するだけで、筆記体の文章を生成できます。
離散値の例としてテキストデータを、連続値の例として筆記体を扱います。それから、筆記体の文章を合成します。この筆記体の文章は、リアルさを保ったまま、筆跡を様々に変えることができます。
引用数
2020/03/17 2323
Convolutional-recursive deep learning for 3D object classification(2012, NIPS)
クリックして4773-convolutional-recursive-deep-learning-for-3d-object-classification.pdfにアクセス
Citation > 449
概要
- 2 layer CNN + fixed-tree RNNというアーキテクチャは優れている
- RNNのウェイトを固定乱数にしても分類性能が高い
- RGBD imageがinputだが、Dを適切に扱えておらず(see Figure2)、追加チャンネルとしてしか使えていない。
Category-Separating Strategy for branded handbag recognition(2014)
https://ieeexplore.ieee.org/document/6877816
citation > 3
- checker patternを表すフィーチャーを手で作る
- SIFT + SVM
“fine-grained object detection”と謳っているが、厳しいな・・・
A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning (2008 ICML)
http://machinelearning.org/archive/icml2008/papers/391.pdf
引用数
> 2830
2つのデータセットがあって、それぞれ小さくて、うまくマージできないときにどうすればいいかという話なのだが、
weightを共有し(つまり単一モデルを使い)、データセットAとデータセットBからランダムサンプルしてweight updateに使う。
この際にデータセットAとBの重複部分の扱いが問題になるが、Lookup tableを用意してどうにかする。
Multitask learning自体は1997年に遡る。
Two-Stream Convolutional Networks for Action Recognition in Videos(2014 nips)
https://arxiv.org/abs/1406.2199
引用数
> 2017
概要
two-streams hypothesisによると、人間の視覚野は
- 静的画像解析
- 動き部分の差分抽出
の2つの機能で構成されていると考えられている。
この2つをConvNetで実装し、ガッチャンこさせる論文のようだ。
動き部分の差分抽出には”Optical flow stacking”を使う。
これは画像をRGBの3チャンネルではなく、3+2Lチャンネルに拡張する方法で、L個の速度ベクトルをstackしたものである。
まず、optical flowは、frame tからt+1までにピクセルが移動した移動ベクトルを各点で計算するものである。
これらのベクトルは1つあたり2チャンネルとしてstackできる。stackしたものは当然ながらdense表現となり性能が良い。
当然のような気がするが、かなり性能が上がっている。
ただデータセットが怪しく思える。当時は合計100kぐらいしかなかった。結局ImageNetの2012ILS…にpretrainedを頼っている。
Hybrid computing using a neural network with dynamic external memory (2016 Nature)
https://www.nature.com/articles/nature20101
引用数 > 430
アーキテクチャ
Neural Turing Machineに「メモリー」をくっつけグレードアップしたもの。
本来のメモリーはアドレスを入力してデータを出力するものだが、これはNNで実装できそうだという発想。
何が嬉しいかというと、End-to-Endトレーニングが可能になること。
肝は、attentionに3種類あること
- content lookup
- record the log of consecutive write
- memory allocation
それぞれ、目的があり、
- 連想配列を実装する
- Sequential Readを実装する
- mallocを実装する
ことが目的になっている。
タスク
タスクの中でもDNCにしかないのは、「データ構造の学習」
(長期予測はまぁ、LSTMでも良さげ)
MobileNetV2: Inverted Residuals and Linear Bottlenecks (IEEE: 2018)
https://arxiv.org/abs/1801.04381
引用数
48以上
概要
メモリがめっちゃないデバイスで動くDNNを作った。
ポイント
強いモジュールが3つ出てきて、最後に合体ロボになるところがポイント。
- Deep Separable Convolution
- depthwize / dwize
- pointwize / pwize
- Bottleneck Convolution
- Bottleneck Residual Block
これらが合体して
→Bottleneck Depth Separable Convolutionに!
革命的だったのは、resnetで導入されたskip connectionを、「次元圧縮された層同士で」結合すること。これは、低次元空間のほうが、元の高次元空間よりも容易にゼロを学習できることを示している。
Pictorial Structures Revisited: People Detection and Articulated Pose Estimation(IEEE:2009)
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.395.158&rep=rep1&type=pdf
引用
>762
概要
人間1人のPoseを推定する
見どころ
体のパーツを、長方形がツリーになったものと考える。長方形の座標は(x,y,θ,s)。そう。2Dなの。立体角とかは言っていない。
これをベイズ推定するのがポーズ推定の問題設定。いわゆる生成モデルである
p(L|Image) ∝ p(Image|L)p(L)
p(L)をkinematic priorという。これは各p(l)の掛け算でしかない。
p(L|Image)をMarginal posteriorという。これをベイズ推定するためにlikelihoodを考えるが、2009年の段階ではGaussianとしてモデリングしていた。
p(l_i|l_j ) = N
こんな感じで、トレーニングするが、トレーニング方法に言及がないような・・・?ガウシアンモデリングで生成モデルだから、どうせEM法かな?と思ってたら、Exact法らしい。教師データが少ないし、分布はガウシアンだから容易にサンプリングするのでしょう。marginalについては、
max-product algorithm
sum- product algorithm
で算出する。以上。
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture(ICCV:2015)
概要
CNNでdepthを推定
引用
>684
著者
NYUniv, FaceBookAI
https://scholar.google.co.jp/citations?user=GgQ9GEkAAAAJ&hl=ja&oi=sra
Rob Fergusは評価用データセット(NYUDepth)の作成にも関わっている:
見所
1. Intro
off-the-shelf regression modelsを提供すると宣言している。どこで回収されているのか?
3. Model Architecture
普通のEndToEndモデルじゃない?間違ってるのかな
4.1 Depth Loss
depthの差のgradientのL2を入れている。深度の局所構造の類似をLossに含めているのだ
4.2 法線のLoss
は、単に内積。
Lossはどれもnで正規化している以外は、係数(ハイパーパラメータ)を持っていない。
5. Trainingの工夫
層1と2(圧縮)の学習を完了してから、層3(解像度復元)を単独でトレーニングする方法。
6. evaluation
例えスコアが0.988であろうとも、depthの結果は目で見ると不満足だ(Qualitative)
スコアに頼ってはいけなそうだ。
DeepContour(CVPR 2015)
Citation > 160
Abstract:
輪郭をCNNで検出するのですが、教師データ(手書きの輪郭)をまず細切れにしてクラスタリングしておき、複数クラス分類にして、さらにloss functionをnovelにしたので性能が上がった
まとめ:
F値は76です。Canny Edge DetectorがF=60、人間がF=80であることを考えると確かにいい。
HOG: Histograms of Oriented Gradients for Human Detection(CVPR 2005)
Citation > 23000
Abstract
人間の検出が出来るdescriptorを見つけた
所感
画像をセルに分割し、各セルでImage Gradient Orientationを計算し、その正規化したヒストグラムをセルごとに見て、第一成分を抽出していくと、輪郭が取れるという手法。
輪郭のように綺麗なパターンにならなくとも、SVMのような非線形な分類器で分類が可能。
この論文読むときの注意点としては、window>block>cellの違い。
window: この検出器は古いので、固定の大きさの物体しか検出できない。この大きさを事前に設定しなければならない。これがdetection window(原論文§2)
cell: cellは10×10=100ピクセルなどのピクセル集合であるが、”vote”という概念でヒストグラムに主にθ=tan^(-1)について投票を行う。すなわち、1cell=100ピクセルが20度ずつ分解する場合、9次元ベクトルに圧縮される。ゆえにcell≒9次元ベクトル(原論文§6.3)
block: cellの集合体であり、正規化に使う。これは、画像内の明るさ格差を考慮したものであり、各cellの近傍と考えられる。ゆえにoverlapping blocksという。(原論文§3)
例) HOGが9万次元だ。なぜ?
答) 90000 = 9(1cell=角度ビンの個数) x 2 x 2(そのcellを含むblock数) x 50 x 50(cellの個数)
お分かりだろうか?
“GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts(2004 siggraph)
Citation > 5100
Abstract
foreground extractionをグラフを使って定式化する場合、ピクセルが近接ピクセルとエッジを結んで作るGridグラフの問題になるので、統計物理でいうIsingモデルを拡張したようなモデルになる。
今回は、長方形選択を事前確率として、Bayesモデルとして更新していき、argminとなる母数(各ピクセルの関数で、foregroundであるbelief)を求める。
更新に使うデータは、grabと言って、foregroundに当たる部分を白いピクセルでユーザーにマウスなどでカーブを入力させ、backgroundに当たる部分は黒いピクセルで入力させる操作である。
概要やサンプル画像はメッシ画像を使った説明がわかりやすい。
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_imgproc/py_grabcut/py_grabcut.html
KAZE Features(ECCV 2012)
Citation > 400
風アルゴリズム。風が吹き、画像から情報のない凹凸が消えていく感じのアルゴリズム。
知的好奇心を刺激される。
Abstract:
数理:
反応拡散系を使ってDoGより良いものを作っている。
反応拡散系を拡張する自由度として、
ラプラシアンのようなものを使っている(div・grad)
そのため、回転普遍性が高い。
実装:
Additive Operator Splittingという方法で、偏微分方程式の離散化を行っており、
Thomas Methodという解法で、数値解を求めている。
与太話:
反応拡散系は学生の頃、シマウマのチューリングパターンや、cyclic AMPパターンの説明としてしばしば登場していたので、どちらかというと模様を生むイメージが強かった。
KAZEのように模様をなくす感じにも使われるのか。
熱方程式だと思うと、熱が均質化されていくのは当たり前であるが、それをセグメンテーションに使えると思った発想に驚嘆する。
Selective Search for Object Recognition(IJCV, 2013)
http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
古典的な論文だが、実はDiversificationというところで既知の色々なストラテジーを組み合わせている。
Abstract:
- Efficient Graph Based Image Segmentationを使って、候補をいくつも生成
- Bottom-up Groupingの際に、Diversificationという処理をかまして、
- 最大80個の異なる戦術を作成
- ランキングをそのまま使うのではなく、i * Random()を合計してリランキング(上位と下位が入れ替わりやすくなる目的と思われる)
- Ground Truthと、Difficalt FalseをSVMで学習
これにより物体認識の判定のための少数の候補を生成する手法である。
Efficient Graph-Based Image Segmentation(IJCV 2004)
Bottom-up groupingという画像のセグメンテーション手法で、古典的な論文。
CNNアプローチだとBottom-up groupingの原理を学習している可能性があるため調査した。
Abstract:
セグメンテーション問題をグラフで定式化する。
Nearest Neighbor Graph > Grid Graph
という結果が得られる。
チープラーニング(Lin, 2017)
https://arxiv.org/pdf/1608.08225.pdf%5C
CITATION:93 @ April 13, 2018
Abstract:
ディープラーニングの成功は、数学だけでなく物理学にも依存している。 ニューラルネットワークが任意の関数を近似できることは数学の定理により保証されているが、 実用的な関数のクラスは、指数関数的に少ないパラメータしか持たない。 これを「チープラーニング」と呼びたい。
我々は、対称性、局所性、compositionality、polynomial log-probability(訳注:つまり、ガウス分布みたいなもののことね) など、物理学でよく使われる仮定を、ニューラルネットワークの簡約化として実現する。
我々はさらに、ある場合、深いニューラルネットワークが浅いものよりも効率的であると主張する。 それは、データを生成する統計的プロセスが階層構造である場合である(物理や機械学習ではよくあること)。 我々は情報理論を用いてこの主張を定式化し、くりこみ(renormalization)との関係を議論する。 様々な「平坦化不可能性の定理」を証明することで、深いニューラルネットワークを浅いもので正確に近似できず、ロスファンクションが低下するケースを説明する。 例えば、単一の隠れ層では、ニューロンが2のn乗個未満の場合、n個の変数を乗算することができないという事実に説明を与える。
医療へのRNNの応用 – 時系列から、病名を予測 -(Lipton, 2016)
http://proceedings.mlr.press/v56/Lipton16.pdf
Abstract
我々は、臨床からの時系列のデータ欠損問題への解答を示す。 そのために、病名をクリニックで得られる寺家列データを分類するタスクを考える。 データはロサンゼルス児童病院の小児集中治療室(PICU)から収集した、多変量時系列である。 測定値には不規則な欠損期間があり、その結果、意味が無い時間パターンが生じてしまう。 これらはアーティファクトなので、典型的にはimputation処理されてきた。 しかし、我々はこのアーティファクトをFeatureとし、優れた予測パフォーマンスを達成した。
線形モデルとは異なり、リカレントニューラルネットワークは、欠損のバイナリインジケータを付加することにより精度改善できる。 線形モデルにおいても、この信号を捕捉する別の方法が示せた。
欠損のバイナリインジケータのみでモデルを訓練する実験も行った。 病名だけでなく、どのような検査が行われるかも予測可能である。
1. Introduction
病院の集中治療室ユニットは、電子健康記録(EHR)に大量の入院患者のデータを記録する。 臨床スタッフは、毎時間の見回りの時や、患者が不安定な状態に陥った時、必ずバイタルサインチャートを描く。 EHRは、ラボの検査結果や、医師や看護師の指示に応じて処方された薬も記録する。 結果として、EHRは、クリニックで生まれるデータの大部分を記録しており、患者の健康状態と受けたケアの両方を含んでいる。
我々は、病名診断を含む応用のための正確な予測モデルを構築するために、これらの時系列を掘り下げたい。 リカレントニューラルネットワーク(RNN)は、時系列からシーケンスを学習したり、一時的な相関を学習できる。 RNNは、自然言語処理、音声、ビデオ、手書きなど、多くのシーケンス学習の分野で、かつてない予測能力を発揮している。 2016年に著者=Liptonらは臨床時系列データにおける病名分類でのRNNの有効性を示した。
Youtubeの次の再生をディープラーニングでランキング予測(Covington , 2016)
2. SYSTEM OVERVIEW
システムは
- NN1: 候補生成
- NN2: ランキング生成
から成っている。
候補生成は、ユーザの活動履歴入力とし、ビデオからなるコーパスのサブセットを出力とする。
候補は、いろんな意味でユーザーに「近く」なるように生成される。
候補生成は一般的な協調フィルタリングによるパーソナライゼーションで行う。
類似度関数に食わせるfeatureは閲覧ビデオのID・検索クエリをトークン化したもの、および人口統計である。粗いfeatureで妥協していると言える。
リストに2〜3個の「ベスト」なリコメンドを表出するには高解像度のfeatureが必要となってしまう。
なぜなら、recallが高いアイテム間をちゃんと区別できないといけないからである。
ランキング生成は、ビデオとユーザの高解像度のfeatureから目的関数を計算して、それをスコアとして各候補に割りあてる。
最もスコアが高いビデオから、ユーザーに提示される。
2段階リコメンドアーキテクチャのおかげで、1段階目では数百万候補のCFができ、2段階目ではユーザーにとって魅力的な少数の選択肢のみが残るようにできる。
さらに、以前の研究[3]で記述されているような、混合ソースの候補生成を可能にする。
開発時は、precision, recall, ranking-lossといったメトリクスを使って反復的な改善を行っており、
アルゴリズムやモデルの有効性は最終的には、A/Bテストで判断する。A/Bテストでは、click through rate, 視聴時間, ユーザーエンゲージメントを測定する多くのメトリックを測定する。
A/Bテストの結果は常にオフライン実験と相関するとは限らない。
3 候補生成
候補生成過程で、数百万のYouTube動画からなるコーパスは、ユーザーに関連する可能性のある数百の動画にまで減る。前身のリコメンドアーキテクチャは、ランキングロス関数でMatrix Factorization。
ニューラルネットワークにしてから何度か改善を行ったが、初期は、ユーザの閲覧履歴を浅いネットワークに食わせて、MFの動作を模倣した。 よって、我々のアプローチは、MFを非線形に汎化したものだ。
3.1 分類器によるリコメンド
時刻tにビデオ閲覧w(t)をリコメンドすることを、選択肢が極端に多いマルチクラス分類器として行う。式は、ユーザの埋め込みベクトルと、ビデオのフィーチャーの埋め込みベクトルの内積を指数関数に入れて生成確率とする。
このアーキテクチャでは、埋め込みは、sparseをdense空間へマッピングすることである。ディープニューラルネットワークに与えるタスクは、ユーザ埋め込みを行動履歴とコンテキストの関数として学習するタスクである。その表現は、softmax分類器を用いてビデオを分類するのに有用なものとなる。
YouTubeにはthumb up, down, 社内集計, などの明示的なフィードバックがあるが、リコメンドに食わせてはいない。リコメンドに食わせているのは、閲覧履歴すなわち暗黙のフィードバックである。この理由は、テールでは明示的なフィードバックが極端に少なくsparseで、リコメンドが機能しなくなるからだ。
3.2 Model Architecture (候補生成)
連続的bag of wordsからの連想で、 まず各ビデオの高次元埋め込みを学習しこれらの埋め込みをフィードフォワードニューラルネットワークに供給する。
ユーザーの視聴履歴可変長のsparseなビデオIDシーケンスベクトルですが、denseなベクトル表現に埋め込む。 ネットワークは固定長のdenseベクトルを入力とし、最も成績のよいdenseベクトルの平均をとる。 (sumやcomponent-wise sumなどより好成績でした)
重要なのは、埋め込みは他の全パラメータと同時にgradient descent backpropagation + cross entropy lossで学習されることだ。 各featureは同一の第1層に幅広にconcatされ、 続いて、fully connected層が幾つか続く。アクティベーションはReLU(Figure 3)
(cross entropyは片方の分布が固定ならKLD最小化と同じ)
3.3 Heterogeneous Signals
Matrix Factorizationの一般化としてdnnを使うことの何がいいかって、連続的・カテゴリカルなfeatureをいくらでも簡単にモデルに追加できる。
検索履歴と閲覧履歴と同様に扱う。各クエリはuni-gramとbi-gramにトークン化してから埋め込まれる。 埋め込みを平均化したものは、検索履歴の要約と考えられる。
リコメンドを合理的にするためにデモグラも使う。地理情報、デバイス種別は埋め込み表現として入力するが、単純なものはそのままの値を正規化して使う。性別、ログイン状態、年齢が[0, 1]に正規化して入力される。
3.4 Label & Context Selection
3.5 Features & Depth
…
4 ランク予測
ランク予測の主な役割は、閲覧データを使用して、特定のユーザーインターフェイスの条件下で、候補生成を特殊化し調整することである。 例えば、動画を固定して考え、あるユーザがそれを高い確率でみるとする。そして、サムネイル画像をのクリックして特定のホームページに遷移する可能性が低いとする。 ランク予測中には、候補全て(数百万通り)ではなくたかだか数百の動画にしかスコアがつかないので、その動画のより多様なfeatureやユーザーとそのビデオの関係性のfeatureを使える。 ランク予測は、異なるソースから生成されたためにスコアを直接比較できないような候補のアンサンブルに対しても適用可能であるというメリットがある。
我々は候補生成と似た構造のディープニューラルネットワークを使って、各動画の各インプレッションに独立にスコアを割り当てることができる。 このスコアの計算には、DNNの最終アウトプットに対してWeightedロジスティック回帰を適用する。動画のリストはこのスコアでソートされ、ユーザーに出力される。 ランク予測の最終的な目的関数は、ライブのA/Bテストの結果に基づいて調整され続けているが、シンプルな関数である。 これは、リコメンド1インプレッションあたりのビデオの期待閲覧回数の、関数である。 クリックするーだけでランク予測をしてしまうと、ユーザーが結局は途中でやめてしまった動画が大量に入り込んできてランク予測が悪化するが、閲覧時間の長さまで使うと、エンゲージメントをよく捕捉できる。
4.1 Feature Representation
ニューラルネットワークは、決定木やそのアンサンブルよりも入力のスケーリングで壊れやすい。連続特徴の適切な正規化が収束にとって重要であることがわかった。具体的には、累積分布が[0,1]に均等に分布するように値をスケーリングした。
この正規化定数の積分は、featureの4分値間を線形補間したもので近似する。
またx(閲覧経過時間など)に対してx^2やx^0.5もfeatureとして採用した。これにより、上に凸や下に凸の場合を容易に再現する。これによりオフライン精度の向上を確認した。
Latent Dirichlet Allocation(LDA)
(リンク)
Abstract
LDAは、生成モデルであり、テキストコーパスのような離散データを対象とする。
LDAは、3層の階層ベイズモデルで、各アイテムを潜在的なトピックの重ね合わせとしてモデリングする。逆に各トピックは、トピックの確率分布の重ねあわせとしてモデリングされる。
テキストモデリングの文脈で、トピックの確率はドキュメントの表現を与えると考えられる。
我々は、変分ベイズ法とEMアルゴリズムに基づいた効率的な近似的推論アルゴリズムを示す。
我々は、ドキュメントモデリングの結果と、テキスト分類、協調フィルタリングの結果を提示し、ユニグラムモデルやLSIモデルとの比較を行う。
1. Introduction
この論文ではテキストコーパスやその他の離散データの問題について触れる。
目標は、効率的な処理を可能にする一方、テキスト分類やノベルティ検出、要約、類似性や関連性判定といったことを可能にする統計的性質を壊さないような、データ表現を見出すことである。
この問題については、IRの分野でかなりの発展が見られる。
基本的な方法は、インターネット検索で実用されているもので、各ドキュメントを単語回数ベクトルに変換するというものである。
有名なTF-IDF法では、基本的な語彙がまず選ばれ、コーパス中の各ドキュメントに対して、単語の生起回数が数えられる。適当な正規化の後、この生起頻度はドキュメントの頻度の逆数をかけられる。ドキュメントの頻度は、コーパス全体にこの単語がどれだけ現れるかの尺度である(通常対数をとって正規化される)。
結果は単語-ドキュメント行列となり、各カラムが各ドキュメントに対するTF-IDF値を格納する。
よって、TF-IDF法はドキュメントを固定長のベクトルに変換できる。
TF-IDFには魅力的な性質がある。特に、ドキュメントを特徴づける単語の集合を特定できる点である。このアプローチはドキュメントをかなり小さいサイズに変換できるが、ドキュメント間の統計的関連性についてはほとんど明らかにしない。
この結果を説明するために、IRの研究者は他の次元縮約法を見出した。最も有名なのは、Latent Semantic Indexing(LSI法)である。
LSIは行列の特異値分解を使って、TF-IDF法の特徴空間の部分空間を得る。その部分空間は、最も分散の大きい部分に対応する。
このアプローチは、大きなデータをかなり圧縮する。しかも、DeerwesterらはLSIが導き出した特徴ベクトルは、TF-IDFの特徴ベクトルの線型結合だが、synonymy(同義語)やpolysemy(多義語)などの言語的特長を表現していると主張した。
このLSIの主張を実証するため、またLSIの強みと弱みを調べるためには、確率的生成モデルを使ってテキストコーパスを分析し、LSIが生成モデルの性質をデータから再現できるかを見るのが有効である。
しかしテキストの生成モデルが与えられても、なぜLSI法を採用すべきかは自明とは言いがたい。むしろ直接的に、最尤推定やベイズ推定を使ってフィッティングすることも出来る。
この方法を大きく発展させたのはHofmann(1999)で、確率的LSIモデル(別名アスペクトモデル)を提示した。pLSIについては§4.3で触れるが、ドキュメント中の各単語を多項分布の重ねあわせからランダムサンプリングする方法である。この多項分布は”トピック”であると解釈される。
だから単一トピックから各単語が生成され、ドキュメント中の異なる単語は異なるトピックから生成されているかもしれない。各ドキュメントは複数のトピックの混合されたもので、トピック集合の上の確率分布だと考えられる。この確率分布はドキュメントの”縮約表現”と呼ばれる。
Hofmannの研究がテキストの確率的モデリングに一石を投じたとはいえ、pLSIはドキュメントレベルでの確率モデルを構成できない不完全なものである。
pLSIでは各ドキュメントは数のリストで、これらの数を生成する確率モデルを持たない。
これにより以下の問題が生じる。
- モデルのパラメータの数がコーパスのサイズに線型に比例し、過学習を起こす
- ドキュメントに対してどう確率を割り当てるかが決まっていない。
pLSIの先に行くためには、次のような基礎的な確率に関する要請を行う。この要請は、LSIやpLSIなど、次元縮約を行うモデルにつきものである。
それは、ドキュメントが”bag-of-words”であるという要請である。つまり、ドキュメント中の単語の順番は無視して構わないと言う前提を置いている。
確率論の言葉では、ドキュメント中の単語の置換にたいする不偏性の要請と言える。
さらに、明示されることは少ないとはいえ、これらの方法はコーパス中のドキュメントの順番も無視して構わないと言う前提を置いている。
de Finetti(1990)にさかのぼる、古典的な表現定理では、置換可能な確率変数は、無限個の確率分布の混合分布で表現されるとしている。
だから、もしわれわれがドキュメントや単語を置換可能とするなら、混合分布モデルを考えなければならない。
この考えに従ったのが、我々の提案するLatent Dirichlet Allocation(LDA)である。
最も強調されるべきは、この置換可能性は確率変数の独立性や一様分布性を意味しないと言うことである。むしろ、置換可能性は”条件付き独立かつ一様分布”と解釈できる。それは、潜在変数(latent variable)についての条件付き確率分布である。
条件付きで、これらの確率変数の同時分布は単純かつ分解可能になる。ただし、潜在変数で周辺化した場合、複雑かつ分解不能になることに注意すべきである。
だから、テキストモデリングの分野では置換可能性は単純化を意味し、計算が効率的に可能であることを意味するが、必ずしも単純な頻度確率や線型操作を意味しない。
我々の目的は、de Finettiの定理をこれらの混合分布に真面目に適用すると、ドキュメント間の統計的関連性を捉えることが出来ることを示すことである。
また、このことにも触れておかなければいけない。置換可能性の一般化はたくさんある。その中には部分置換可能性もあり、表現定理も同様に適用できる。
だから、我々のモデルが”bag-of-words”モデルしか扱っていないとはいえ、我々の方法はもっと順序を考慮したモデル、例えばn-gramや段落モデルにも適用できるはずだと言うことである。
この論文の構成は次の通りである。§2では基本的な用語や表記法を導入する。
LDAモデルは§3で登場し、§4で関連のある潜在変数モデルと比較される。
パラメータ推定については§5で議論される。
目覚しい成果、LDAをデータにどう適合させるかについては§6で扱う。
テキストモデリング、テキスト分類、協調フィルタリングについての実験結果は§7で提示される。
最後に、§8で結論を述べる。
補足:Latentモデルとは
LatentモデルとはLatent変数を持つモデルです。Latentとは潜在的、という意味で、隠れ変数とも呼ばれます。直接は観測できないが、モデルに存在する隠れ変数のことを意味しています。
もっとも有名なLatentモデルは、Gaussian Mixture(GMM)です。これは、データ点の分布が、いくつかの正規分布から生み出されると仮定します。
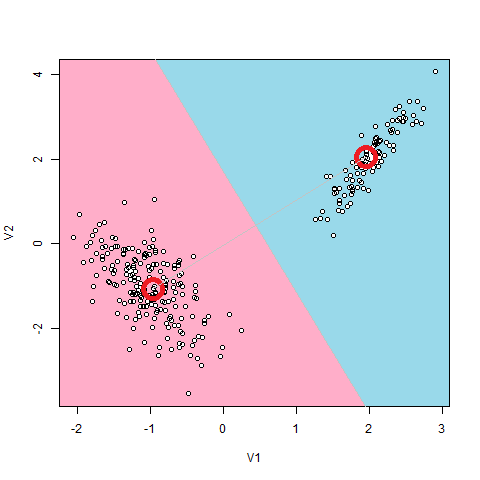
例えば上図のように、2つの塊になっている点分布の場合、2つの正規分布からデータが生成されていると仮定するのが自然でしょう。
このモデルにおけるLatent変数とは、2つの正規分布のどちらから生成されたのかという2つの値をとりうるカテゴリカル変数です。これらは、データ1個1個から直接は観測できない変数になっています。
補足:LDAにおけるLatent変数
LDAのLatent変数は、Dirichlet分布に従う「トピックID」です。
例えばLDAで文章を解析する場合、文章の主題の種類をトピックといいます。例えば、タイガーウッズが不倫をしているという文章があったとします。
タイガーウッズは〇〇大会で輝かしい実績を残した。(文章A)
そのタイガーウッズが△△と不倫をした。(文章B)
タイガーウッズは来月に□□大会を控えている。(文章C)架空のニュース
この場合、文章AとCのトピックはゴルフ、文章Bのトピックは不倫と言えます。
このことはLDAでは、その文章が「ゴルフについてなのか」「不倫についてなのか」という2択を表す隠れ変数がDirichlet分布に従うように、モデリングしていることになります。
その意味で、正規分布の混合分布のLatent変数と同じカテゴリカル変数といえます。