Table of Contents
具体的に並列計算とは何を指すのか
並列計算についてはThread(Java)から数えても20年立っており、生半可な知識で語るとマサカリが飛んでくるようなトピックです。使ったことがあると自信を持って言えるものについてだけ語りたいと思っています。技術名(言語名)
- pthread(C++)
- Thread(Java)
- ThreadLocal(Java)
- Semaphore(?)
- ThreadPool(Java)
- Concurrent(Java)
- xargs(shell)
- CUDA(C)
- Observer(Java)
- Promise(javascript)
- Future(Scala)
- Tryモナド(Scala)
- HDFS(Java)
- Cassandra
- Hadoop(Java)
- Hive(Java)
- Spark(Scala)
- kafka(Java)
- Samsa(Java)
- InfiniBand/DGX(?)
- BigQuery(Google)
よく知らないけどビッグネームだし語っちゃえというもの
- Google File System(?)
- MapReduce(?)
- BigTable(?)
- Dremel(?)
- Colossus(?)
- MegaStore(?)
- Millwheel(?)
- CouchDB
- MongoDB
- Vertica(?)
- TensorFlow on Spark(?)
- FaunaDB(?)
- ABCI(?)
- TPU(?)
未習熟・知らない・トラウマがあるなどの理由で語れないもの
- MPI(C)
- Folly(Facebook)
- multiprocessing(python)
- pprocess(python)
- OpenCL/ヘテロジーニアスコンピューティング(?)
- Rx(Java)
- coroutine(Kotlin)
- Akka(Scala)
- Athena(Amazon)
…44個。リスト作っただけでうわっとなり、やっぱやめようかと悩むも、知っている限りのことは書いて公開してしまうことにした。
スケールアップ系の並列計算
粒度粗い(プロセス単位)
物理の研究室にいた時、みんなプログラミングは道具だとか言っていてやばかったので、Fortranをビルドして以下のようにしていた。topコマンドをうつとa.outだらけで悲惨なことになっていたものである。
|
1 |
ssh host_n ~/a.out # 手動で繰り返す |
社会人はxargsを使う。
|
1 |
xargs -P コア数 |
python系のライブラリは、(あんま使ったことないけど)xargsで分散するのと性能的に大差なかったという体験がある。numpyが爆速だからであろう。それ以降、気軽にxargs -P 20とかしてる。運が良ければ全コアの利用率も100%になる。
デメリットは、同じファイルを複数プロセスで読み書きすると死ぬことだろうか。
粒度細かい(関数単位)
- pthread(C++)
- Thread(Java)
- ThreadLocal(Java)
- Concurrent(Java)
CPUの1コアで2スレッドずつ実行させることで、全コアの利用率を100%にしようみたいな思想がこれである。メリットは、並列化するコードの範囲が狭くて済むのでボトルネックだけ並列化すればいいので、開発工数が低く故障箇所も狭いということだろうか。
しかしその狭い故障箇所が死ぬほど故障するのである。
排他制御のことをmutexという。mutexを人力で管理するのは、memoryを人力(参照カウンタとか)で管理するぐらい難しい。感覚的にはマシン語ぐらい難しい。結果を可視化するのが自分の脳に無理という意味で。人力では無理なのでTDDしてTestをたくさん書くぐらいしかないのではないだろうか。
有名なのはJavaのsynchronizedである。これこそmutexを手動管理する方法であった。当初はsynchronizedブロックの中のコードは1スレッドのみによって実行されるから問題は起こらないはず、とされていたが、現代から見ると浅すぎる想定である。synchronized自体の仕様が人知を超えた複雑さであったため、ほとんど役に立たなかった。(これが何を言ってるかわからないという人は、多分synchronizedが引き起こす障害の対応をしたことがない)
|
1 2 3 |
synchronized { ... } |
mutexをくぐり抜け、各スレッドが正常終了した後に、結果をまとめる必要がある。joinだとか色々APIがあるが、結局は同期させて全部終わるまで待つことになる。これをブロッキングという。
Concurrentはmutexを人間に理解可能にすべく綺麗にしたものだと思う。気に入って長く使っていた。作者が以下のような本を書いているが、ちゃんと読むと半年以上かかってしまうほど難しい。(2020年現在はGoetzを読むよりFutureを呼んだ方がいい)

セマフォとConcurrent
多分Goetz(もしくは共同開発者)が、初めてセマフォをJavaのThreadに応用することを考えたのだと思う。セマフォとはレンタカーみたいなオブジェクトで、総台数を保ったままリソースを貸し出す仕組みである。JavaのConcurrentというライブラリが公式に作られた。
これはServletにおいてはThreadPoolというものになった。Threadをnewすると、使われていないThreadが無制限に増えてしまう。そこで、ThreadPoolに「貸してくれ」という。ThreadPoolが満員だと、誰かがThreadを使い終わって返却してくれるまで待たされる。でもリソースがショートすることはない。これは当時超発明だと思って興奮していた。
Oracleの功罪
思うにJavaのThreadが一番便利だったのは、「WebServlet」が時代を切り開いたからだろうと思う。2008年とかにWebアプリを作り始めたが、当時は今のTwitterみたいに兆単位のPVとかはありえなかった。むしろ、インターネット向けではなくイントラ向けのアプリとか作っていた。要は社内LANからしかアクセスがないので、同時に5人ぐらい捌ければ御の字というわけである。

(1996年当時世界初とか言っていたが、要はそんなに競合が無かったということらしい)
それでも、javascript(AJAX)が進化して1ユーザーからバンバンリクエストが飛ぶようになり、秒間100→1000→10000アクセス捌けるWebサーバーがもてはやされることとなった。これをThreadを使ってうまく処理するのがWebServletというソフト(JavaEE)である。Webサーバーが次のように豪華になっていった。
- Apache
- Tomcat
- GlassFish
- (有料)Solaris/WebSphere
IBMに頼むと、WebSphereがインストールされたサーバー1台とOracleがインストールされたサーバー1台をセットでとんでもない値段で売りつけてきたものである。
だからThreadを発展させたのはOracleのおかげだと言える。後述するように、スケールアップにおける究極系であるExaDataに結実する。さすがエンタープライズ向けで世界一位の会社だ。
Oracleの罪な部分は、マルチノードDBが全然使い物にならなかったところである。つまりOracleはスケールアップしか商品化できていなかった。2015年ぐらいになってOracleは分散システムを売り始めたが、商談に行くと普通にkafkaとGoldenGate買わない?などと言われたものである。kafkaはオープンソースだし、GoldenGateはOracleから独立起業した社員が書いたソフトウェアだ。

粒度超細かい(分岐しない処理単位)
GPUとCUDAの話を書く。
まずGPUというのはALUよりも簡単な計算ユニットを、感覚的には1000個以上集積したチップである。計算できない命令がある代わりに、同一命令の多数データに対する一括計算ができる。感覚的には、行列の全要素に対し同一命令を1クロックで行える感じだ。
NVIDIAはアートワークがうまい。以下の画像はクッソかっこいい。

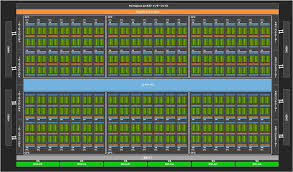
コア数も多い。
- 5,376 個の FP32 コア
- 5,376 個の INT32コア
- 2,688 個の FP64 コア
- 672 個の Tensor コア
- 336 個のテクスチャ ユニット
しかし速度は一概にCPUとコア数で比較できないものである。面倒なので、Volta100がCPU1コアの100倍速い、と覚えることにしている。
昔はもっとひどかったが、以下のような面倒なコードを書くことになる。Matrixではダメで、GpuMatrixにしないとGpuメモリに転送されない。当然行列要素はGPUのコア数より大きいので、GPUのスケジューラーによって段階的に実行されるので1クロックでは処理されない。
|
1 2 3 4 5 6 7 8 9 |
cv::Mat h_src1(cv::Size(width, height), CV_8UC1, cv::Scalar(1)); cv::Mat h_src2(h_src1.size(), h_src1.type(), cv::Scalar(10)); cv::Mat h_dst(h_src1.size(), h_src1.type()); cv::cuda::GpuMat d_src1(h_src1); cv::cuda::GpuMat d_src2(h_src2); cv::cuda::GpuMat d_dst(h_dst); cv::cuda::multiply(d_src1, d_src2, d_dst, scale); |
どのくらい速くなるかであるが、10万円ぐらいの1080Tiだと行列計算は20倍ぐらいにしかならない。なぜかというと、CPUメモリからGPUメモリに行列を転送/逆転送する時間がかかるからである。
さらに、GPUには実行できない命令があるので、そこはCPUで計算されるので、実際にはプログラムの速度は2倍にしかならないということも往々にある。
ともあれ、V100でCPUの100倍速くなると根拠なく信じた人がいたので、NVIDIA株は爆上げした。遊びに行くと黒い革ジャンを着たCEOジェン・スン・フアンがクリスピー・クリーム・ドーナツをその場にいる100人ぐらいの人にばら撒いていた。
ちなみに行列計算が分散できる事実を説明なしに使ったが、行列演算の分解についてはMatrix Fragmentation/Matrix Multiply Accumulateで調べるといい。CUDA9以降は、このMMA演算専用のチップであるTensorCoreを呼び出すWMMA(Warp Matrix Multiply Accumulate)というAPIが用意されている。WMMAを検証したところ、チップに変数サイズを合わせないと動かないなどがあり、当時はNVIDIAのDriver開発者にしか使えないような代物であったが。
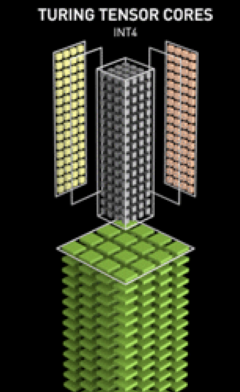
GPUメモリの話が出たので、HBM2を押さえておいてもいいかもしれない。速いメモリを使うことに加え3D回路設計の最適化により、転送時間を少なくする技術だ。1秒に約1TB転送できる。

あとはNVLinkだろうか。2枚のGPUをブリッジするとGPUメモリ間の転送ができる機能だ。DMAの外側にあるDMAみたいな気持ちで捉えている。当然2倍速くはならない。マザーボードを選ぶので、ちょっと高くつく可能性すらある。
なんだかんだGPUはかっこいいので熱く語ってしまった。
粒度超超細かい(命令単位)
なんもわからん
プロセッサ(主にCPU)に特殊な命令セットを用意することで、CPU内部の回路で特定命令だけ分散するということらしい。しかし私には命令セットのリストすらわからん。とりあえず人から聞いたものをここに列挙ぐらいはしておこうと思う
Intel入っtel
- AVX-512 命令セットの vfmadd231ps 命令
AMD
- なんもわからん
粒度超超超細かい(電子回路単位)
私はIC7474シリーズとか半田付けとか大好きであった。
FPGAというのはプログラマブル半導体で特定処理だけをさせることができる。プログラマブル半導体は古くはGALなどもあったが、FPGAのすごいところは高位合成できることだろうか。
そんなうまい話はなく、numpyで1行で書ける行列の積を東工大の中原先生が高位合成で書いていたら、65行かかったらしい。昔FPGAマガジンを買ったことはあるが、ひたすら大変そうなので自分では試していない。(というか発売中止)

C言語でFPGAを高位合成!
かっこいい。
究極系としてはIBMがNetezzaというハードウェアを作ったが、バスの中にFPGAが仕込んであり、where文とかを末端で実行しメモリから弾くことができた。すごいよね。DSPに似た発想だなぁとは思ったが、DSPはバス上にはないからね。

粒度超粗い(高帯域バス・ディスク)
Exadataとは、Oracleがインストールされた高いハードウェアである。
またデータベースではDiskの高速性を測るのに、スループットではなくて何回書き込みができるかというオーバーヘッド評価を重視することが多い。1秒あたりの読み書き回数の上限をIOPSという。
とにかくたくさん高IOPSのハードディスクがあって、Infinibandで超吸い上げを行う。バスを流れるデータは、1時間あたり12TBも転送が可能だという。1秒で3Gの計算なので、英語の本換算で10000冊分ぐらいのテキストデータをロードできる笑
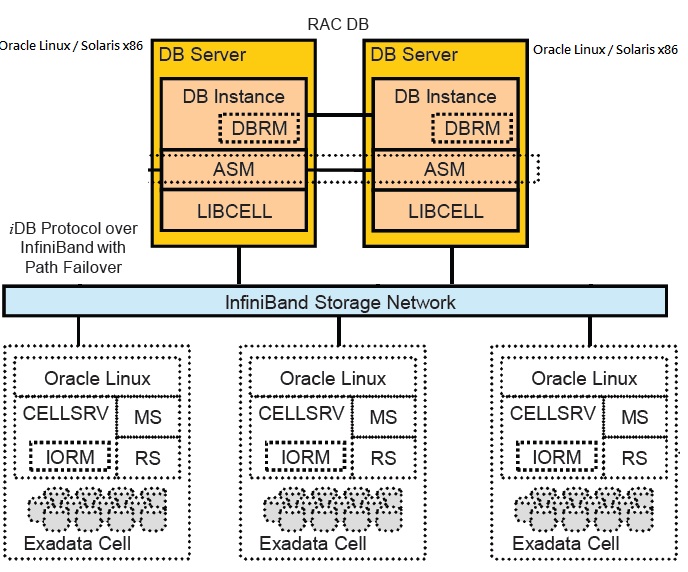
まぁ要はインメモリコンピューティングなんだと理解している。他にも技術の粋が尽くされていて、Exadataの宣伝用パンフレットを読むと、欲しくなると思う。
https://www.oracle.com/technetwork/jp/ondemand/database/db-new/d-3-exadata-1448374-ja.pdf
ExadataはProfilerも充実していて、それをみているだけで幸福感に襲われた。毎日、Exaの画面を見に会社に行っている気分だった。(1年後さすがに飽きた)
ノンブロッキング系の並列計算
Java→Javascript
デザインパターンを覚えないプログラマは車輪の再発明をして死ぬ。そう思われていた時代がありました。

デザインパターンはGUIアプリを作るときによく出てくるパターンで、その中にObserverパターンというものがあった。当時自分としてはプログレスバーを作るのに使っていたような気がする(もう記憶曖昧)
- Observer(Java)
- Rx(Java/Android) 使ったことない
- Promise(javascript)
- Future(Scala)
Observerは、Subjectインターフェースが処理を完了したとき、知っているObserver全てのupdateメソッドを呼ぶという仕組みである。

まぁ確かにパターンなんだろう。単純な概念とはいえ、Observerはpublish/subscribeというプログラムパラダイムを生み出したと思うし、知らないとコード書けないぐらいの代物ではある。
javascriptだと、このupdateによって画面描画がトリガーされたり、onCompleteがトリガーされたりする。要は別名をcallbackというわけである。
Observerはフレームワーク作る側の人が書いてくれるので一般プログラマーはそれと知らずしてPromiseとかを使っているが、フレームワークのminifyしてないバージョンを落として最下層までデバッグすると、グローバル変数を使ったObserverパターンを確認できる。一時期そういう遊びにはまっていた。
Java→Javascript→Scala→Kotlin
ここで何を考えたのか、Scalaの人たちがFutureという神を生み出していた。これは端的に言って天才的な発想だと思う。といってもただのモナドなのでモナドを知ってたら何も感動しないかもしれないが。
並列計算結果は「未確定」「確定」「例外」のいずれかを取りうる。なので、そのいずれかの状態をとるモナドを作る(Eitherモナドのイメージ)。
モナドに入れておくことで、reduceのような集計処理(の登録)が可能になる。Threadが終わらなかったり例外を吐きまくったりするのはいつものことなので、モナドにして地下配線してしまえばいいというのは本当に関数型プログラミングを理解しているなぁと感動した。
これによって、Future全てが確定すれば集計されるし、ひとつでも例外が起これば例外処理がされる、と言った動作が型システムでチェックできる。
Javascriptは真に関数型ではなくモナドは書けないしゆえに型システムチェックもできないので、Promiseチェーンを手で書くという地獄のような仕事になる。具体的には、then・when・parallel・onErrorみたいなものに漏れがあるのかをコンパイル時にチェックできないということだ。マゾやな
このJavascript地獄が生まれた時点に居合わせた(老害だから。。。)ので、こちらも読んでほしい。
Kotlinのcoroutineは途中で中断できたりしてさらに凄いらしいが知らないから語れないのは残念だ。
スケールアウト系の並列計算
ディスクヘッド分散
ビッグデータの時代になって、「集計」が脚光をあびることになった。例えば回帰係数の公式を思い出すと、めっちゃΣ(シグマ)書いてあり、集計するだけでお金が儲かることがわかる。
(x_i-\bar{x})}{\displaystyle \sum_{i=1}^{n} (x_i - \bar{x})^2}")
簡単な式だが、xの平均出すだけでも、元データが10億件とかあると吐きそうになるものである。そんな時代が来るとは誰も思ってなかっただろう。
- Google File System
- HDFS
- Cassandra
- kafka
GFSやHDFSはデータの複製を冗長に保持した。しかし、HDFSは、マスターノードが死ぬとクラスターが死ぬという弱点を持っていた。
Cassandraは2007年にFacebookで開発されたAPシステムであり、Consistencyが得られない。Masterlessという設計思想であるため、Partitionが2つ以上に分断されても生き続けるという原生生物のようなデータベースだ。悪名高い(?)「電車ごっこ」接続により、Consistencyを回復させる処理が定期的に走る。こんなダメな仕様でも当時活躍したのは、Amazonタイムセールのように、「とりあえず注文させれば、たまに品切れが起きても謝ればOK」という「統計的に儲かるシステム」が登場したことが大きい。Netflixというミッションクリティカルでないシステムで使われたこともCassandraの名声を高めた。ワークスでは、CAが必要なシステムでCassandraを使い、Cを保証するためのラッパーライブラリーを組んでる人がいたので、CAP定理を理解することは大事だという反面教師になった。当然Cを保証すれば、Cが保証されるまで待つ必要があり、速度が落ちるだけである。
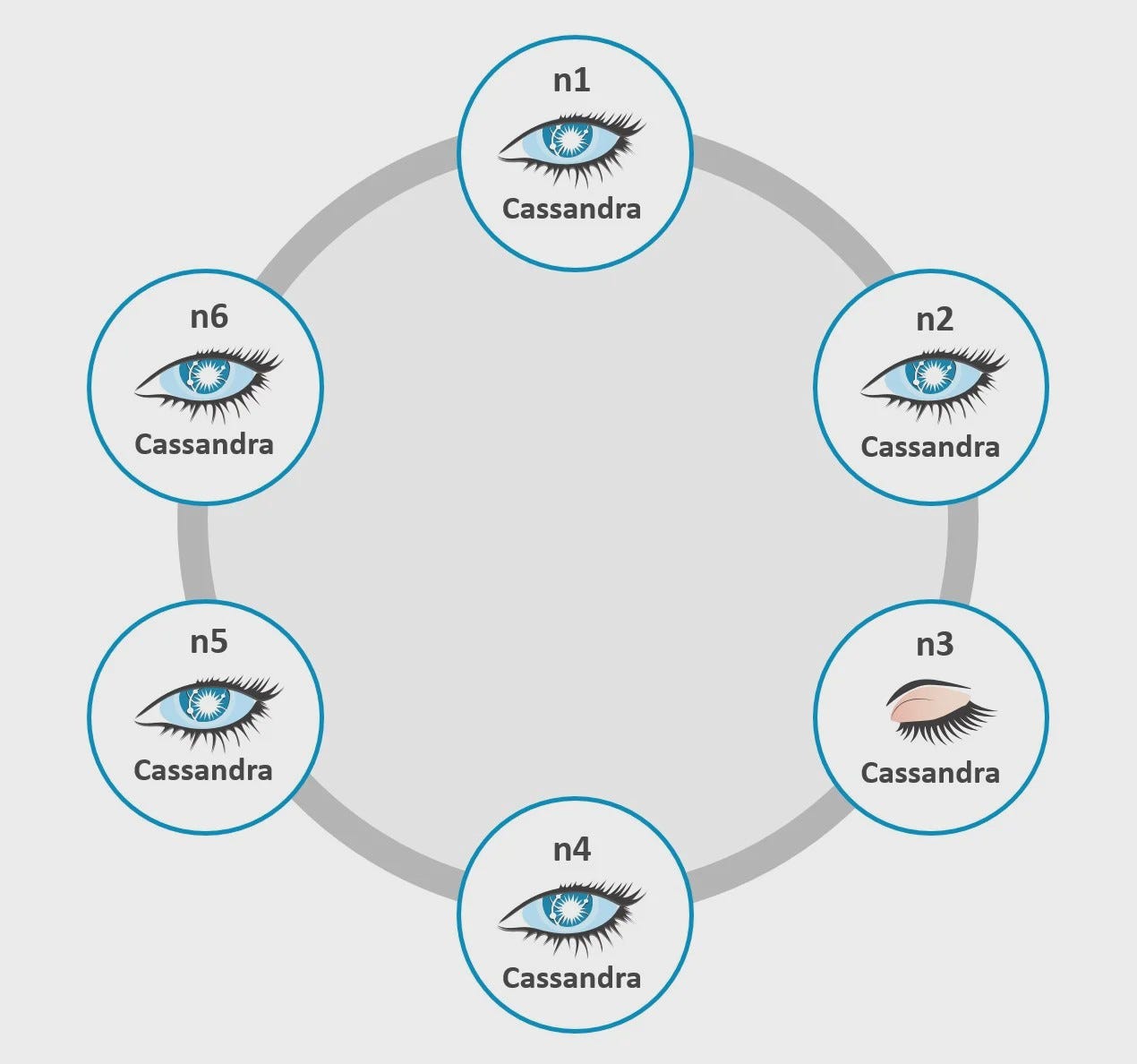
(Consistencyにおいて深刻な問題を抱える)
kafkaはちょっと違う。kafkaはappendしかできない単一の長いログファイルのようなもので、書き込みヘッドを冗長に複数持っている。そしてsubscriptionのヘッドを移動させて、データを一括で読み出す。
Oracleの実装にはREDOログなどがあり、ACIDを実現できる。

要は障害が起きても復元できる。これを他のノードに対して行えば、データの冗長化が出来るのではないか?というアイディアがkafkaである。この冗長化をState-Machine Replicationという。

つまり、CAP定理におけるC=Consistencyと順序保証(timestampによるorder)を担保しているのが単一Logである。
kafkaではLog/write/readをシステム的に分離している。なので、writeヘッドが冗長ということはLogが複数あることを意味しない。単一LogからのReplication先が複数個あるということを意味するにすぎない。readもReplicaについて定義される。Replicaは設定した個数しか作られないので、その全てが分断Partitionの片側に寄る事故が起こり、P耐性がない。
そのため、初期のkafka(2017年10月に0.11が出る以前)ではexactly onceが保証されないCAシステムであったが、Replicaに対して冗長な高速readができ順序保証されるメリットは、メッセンジャーアプリやビッグデータ基盤のETL(Extract Transform Load)にとって有り余るメリットがあったのである。なぜETLでメリットがあるかというと、数GBのcsvを扱うよりも、完全に順序づけされたデータを1件ずつ扱うほうが楽だからである。
単一Log収集で一貫性を持たせるという考え方は当時流行した。例えばLogを検索できるようにするシステムであるELKスタック(Elasticsearch-Kibana)では、Logstashというソフトウェアに色々なシステムで生じるapplication logを集中させる設計が流行った。Logstashが実際に行うのはinputのintegrationとdrop filterぐらいではあるが、必ず必要なので多くのシステムに登場した。しかし、この方法は単一障害点が増えるため、kafkaのようにLogからState-Machine Replicationを行ってCAシステムを置き、Availabilityを上げる(障害点を排除する)設計が歴史的に勝利を収めた。しかし運用コストが高いため、kafkaを使えているのはTech Giantのみだ。なかでもGoldenGateを使ってこの構成にしている企業は数えるほどしかなく、守秘義務を破ることになるので名前も出せない。
つまり貧民のためのkafkaがLogstashなのである。障害が起きた時は欠損データを受け入れるか、もう一度ジョブを回すのである(すると今度はデータ重複が起こる)。Tech Giantでなければ、驚くほど大量のアクセスがくることはまれだ。例えばUberは、1日に1兆件以上の位置データをkafkaでハンドリングしていた。

この発表を聞いた日は夜寝られず、こんな日記を書いてしまった。
Uberの構成にも反映されているが、kafkaの作者Jay Krepsが天才だったのは、「State-Machine Replicationが可能なら、複製先のシステムは同じである必要がない」と気づいたことである。つまり、kafka思想は次のように発展したのだ。
- Logとテーブルは相互変換が可能なので、Logを実態にするデータベースが理論上ありうる。
- Oracleのロールバックの仕組みなどからわかるように、Logさえあれば、データベースの全データを同期できるし、信頼性を上げることができる。
- さらに、State-Machine Replicationの複製先を複数種類の違ったデータベースにすることで、全てのビッグデータインフラにおいて共通のパーツになることができる(原文ではO(N^2)→O(N)という計算量上のメリットについても触れられている。)
Columnar vs Document
ビッグデータ時代になってしまったので、SELECT *みたいなSQLは書くことは無くなった。結果が100GBであれば、転送することすら不可能だからである。
そこに注目したのが、Columnar(カラムナー)データベースだったんじゃないかなと思う。
ColumnarはRowではなくColumn単位でデータを保存するノードを分けるので、例えばwhere文を実行してデータを弾くときに、1ノードだけが動作すればいいという利点があった。これはある意味後述するデータローカリティを意識した実装である。
偉そうに語っているが私はカラムナーを仕事で触ったことはない。DeNAのVertica運用チームに受かったことがあり、そのときに調べさせてもらった。
反対語はドキュメント指向データベースである。なぜ行指向でないのかというと、スキーマレスだから、テーブルという概念自体が存在しないからだ。そこには2次元はなく1次元すなわちドキュメント集合しかないのである。
CouchDBやMongoDBが有名だが使ったことはない。カラムナーがビッグデータ分析の仕事にマッチしていたからだ。なんの責任感もなくいうと、hash関数を使ってドキュメントをO(1)で釣る仕組みだと思っている。極論するとLuceneと同じように捉えている。
データローカリティ
- Hadoop(Java)
- Hive(Java)
- Spark(Scala)
オブジェクト指向的な考えと言っていいのだろうか、データと命令は同じコンピューターにある必要がある。普通に考えると、データをダウンロードしてプログラムを実行する。しかし、HDFSなどのファイルシステムではデータが大きすぎて転送できない。これにより、データローカリティの思想=「プログラムをダウンロードさせた方が速い」が生まれた。
プログラムをどう送るか。Javaなのでjarにして送るのだ。いわゆるmapreduceである。
当時pythonで書くこともできた。Hadoop Streamingという。しかしこの方法はstdin/stdoutを使うため、文字列しか使えない。JSONを使うと冗長になりプログラム量も増える。
Javaは違う。クラスがあり、シリアライズがある。なので、あらゆるSerializableを使うことができた。T implements Serializable / Mapper<T> / Reducer<T>を全てJavaで実装し、jarにしてばらまくというのが由緒正しいMapReduceの作り方だ。
この職業は最初のうちは高給だったが、みんなSQLエンジニアの人海戦術+Hiveに任せて、Hiveで組めないアルゴリズムは放棄するということを選び始めたので、低給になった。
Hiveで組めない処理とは何か。for文である。
これではほぼ全ての機械学習が不可能だが、上記の通り回帰係数を計算すれば儲かる時代には誰もそんなことを気にしなかった。
MapR/Cloudera/HortonWorksというベンチャーが時代を築きとんでもない高給を出して消えていった。
Sparkはちょっと違う。RDDの論文を読もう。
https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
RDDの各コンテナ内ではmapとreduce以外にも任意の処理が実行できる。コンテナにメモリ制限付きではあるが。関数を第一級オブジェクトとしてデータノードに転送し、遅延評価をデータノードで行うようなもので革命的であった。しかも、for文も実行できる。例えばK-meansのようなiterativeな機械学習も実装できるのだ。後年、TensorFlow on Sparkが発明され、DeepLearningが可能になったのも納得である。K-meansをSQLで書くことは出来ないのだから(と思ったらこの後R on Oracleという凄まじいものが発表されるのだが)、もうHiveの役目は終わりなのは明らかであろう。Sparkはオンメモリ処理もあり速かった。
さらに、数年後にGoogleが無限にスケール可能かに見えるSparkクラスターをクラウドサービスとして貸し出し始めた。
これはGoogleが天下とったな、と思ったら、思わぬ落とし穴があった。誰もScalaがかけなかったのだ。Javaすら書けず、みんなSQLしか書けなかったという、MapReduceのHiveへの敗北を再現するかのようであった。
さらに悪かったのは、Sparkはコンテナのメモリが128Mなどと低く、容赦無くjava.lang.OutOfMemoryErrorを吐きまくったことだ。Javaを書ける人でもOutOfMemoryErrorを解決できない人は多い。多くの同僚がメモリーダンプする方法を知らなかったりした。これではみんなSQLを書いてしまうだろう。
初々しかった私はClouderaのSpark研修にも行ってみた。
この流れは止まらず、YARNやらTEZやらでHadoop上で色々な計算ができるようになったり高速化したりした。
さて、Sparkがイマイチ流行らなかった後、トレジャーデータがHiveのUDF(UserDefinedFunction)としてHivemallをリリースしたことで、Hiveでも機械学習ができるようになった。大抵のユースケースはこれで回収されてしまったので、いよいよSparkの立場は無くなった。そう、TensorFlow on Sparkが出るまでは。。。
擬似CAPシステム
Cloud Spannerについて語ろう。Google Blogに書いたこともあるし語らぬわけにはいくまい。
CAP定理というのがあって、
- Consistency
- Availability
- Partition Tolerance
は両立できないことになっている。しかしSpannerは擬似CAPシステムである。
原論文は難解すぎて話題になった。
https://static.googleusercontent.com/media/research.google.com/ja//archive/spanner-osdi2012.pdf
本質的にはAPシステムで、「Eventually Consistent」という概念で動作する。Consistencyを実現するために2回の処理を行うのだが、時間差を計算するとある値以下になることが保証されるので、それをEventuallyと読んでいる。
このあとFaunaDBが出て、GraphQLでクエリーできるようになった。(Faunaの元のCalvinはSpannerと同じ2012年に発明されたらしいが)
マルチノードマルチGPU
InfiniBandの出番である。TensorFlow on Sparkは、Sparkの仕組みを使って全ノードのGPUを勾配計算に使えたら速いという乱暴な考えから生まれた。
私はこれをYahooが発表した時の発表を見ていたので度肝を抜かれた。贅沢でずるい。当時InfiniBandは1個100万円ぐらいしたからだ。
InfiniBandの個数は限られるから、「トポロジー」が重要になる。しかも、問題によって最適なトポロジーが変わる。DGXというシステムでは4枚のGPU同士をどう接続するかというトポロジーを設定ファイルで変更が可能だったが、めちゃくちゃめんどくさい。以下はTencentの論文(“100万枚の画像をたった4分で学習”)である。この論文では、4個のノードそれぞれに4個ずつGPUが載っているので、トポロジーが面倒だというのが伝わるだろう。
paper: https://arxiv.org/abs/1807.11205
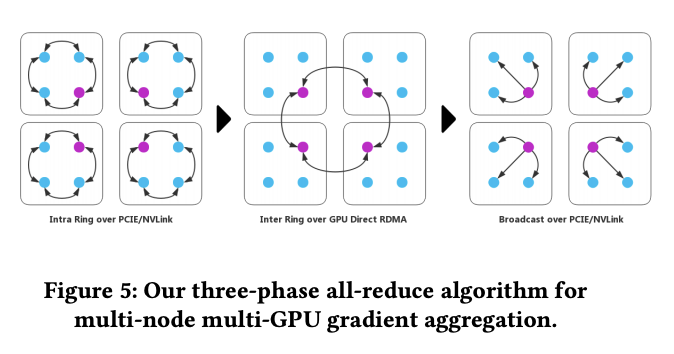
勾配は複数ノードで計算後、集計する必要がある。sync方式とasync方式があるのだが、これを説明するのは流石に面倒臭い。
次がBaiduの作ったRingAllReduce。
https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
https://github.com/baidu-research/baidu-allreduce
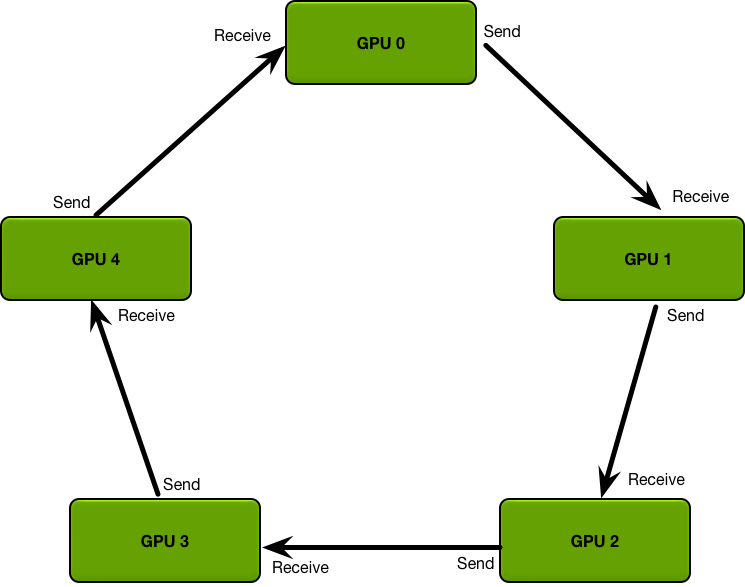
RingAllReduceを発展させたのがSONYの2DTorusである。(“100万枚の画像をたった3分半で学習”)
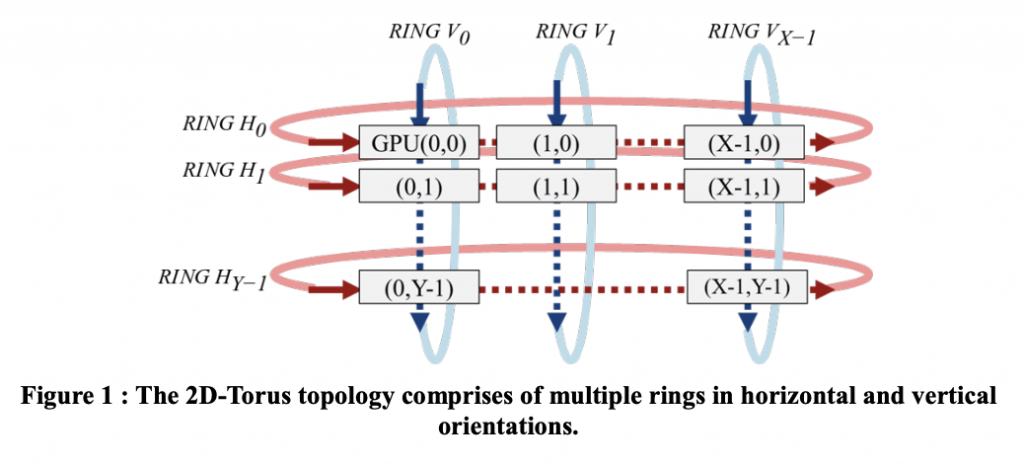
2020年においてもこうしたカスタムシステムであることは変わりなく、例えば1750億パラメーターをtrainしたGPT-3も、Microsoft製のInfiniBandクラスターを利用していると考えられる(論文に若干記述がある)。
計算リソース仮想化
- BigQuery(Google)
- CloudTPU(Google)
そしてGoogleが全てを破壊しにやってきた。
BigQueryのストレージ部分について語る。思想はカラムナーデータベースで、書き込み時に冗長化されている。これがColossusというGFSの発展版のストレージであり、デフォルトで暗号化圧縮済みマネージドスケーラブルストレージなので強い。自分で作ったり立てたりするのはもはや無理で、BigData基盤を運用していた人たちは窮地に立たされた。
BigQueryのロジック実行部分について語る。前身はDremelという名前であり、設計思想が論文にまとまっている。
https://research.google/pubs/pub36632/
BigQueryの設計思想は以下に詳しい。
https://cloud.google.com/files/BigQueryTechnicalWP.pdf
どちらにせよ、小さなメモリを持った仮想コンテナの中で計算は実行される。
Googleは、みんなが毎日使っていたjupyterの形を借りて侵略してきた。collabである。collabではTPUが使える。みんな喜んでいたが、なぜ使えるのかを考えてはいないようだった。TPUが使えるのは、TPUが仮想化され、管理されているからだ。
TPUは1,2,3とバージョンアップしていった。

collabの裏のTPUは、仮想化されているから自然にバージョンが上がっていく。
実はTPU1.0の時点では、必ずしもNVIDIAに対して分のいい戦いという訳では無かった。正直、NVIDIAに負けると思っていた。そもそも、ResNetなどでしか本当の最初期は動いていなかったので、全然勝負になっていなかったように見えた。しかしGoogleが考えていたのは戦い方だった。TPUをまずは仮想化してWeb上から使えるようにしてしまえば、その裏でTPUをバージョンアップしていくことができるのだ。しかし、一度購入してしまったNVIDIAのボードは新しくすることはできない。
仮想化の恩恵はそれだけではない。TPU Podという名前で、TPUクラスタも同じAPIで呼べるようになった。これはもう課金するしかない。
ノンブロッキングはスケールアップ?スケールアウト?
章題が変な日本語になってしまったが、ここで紹介したノンブロッキングのロジックは異質であると感じられたと思う。
結論から言うと、ノンブロッキング処理はスケールアウトである。
Webの黎明期には、Ajaxとは「特定の1台の親サーバー」に対するリクエストであった。しかし、WebAPIの興隆と共に、Ajaxは「複数のIP」に対するリクエストであった。さらに、分散基盤の発展により、「1つのIP=コンピュータークラスター」を意味するようになった。
だから、分散基盤の民主化を進めたのはノンブロッキング処理なのである。ブロッキング処理をしていた時代はどれか1つのAPIが失敗した時点で使い物にならないようなプログラムになりがちで、民主化を阻害していたからである。
今後の更新予定
3日3晩更新し続けたら、自分の知ってることはあらかた書き終えたような気がする。心残りとしては次のようなものを調べて書いてもいいかもしれない。
- TensorFlow on Sparkの後継について
- socketとnode.jsの類似と、Dirtyアプローチについて
- Isomorphic Jsをノンブロッキングのところに容れたい。
むしろ冒頭のリストにあるのに語れなかったものについては理解が足りないのであり、もっと勉強したほうがいいのではないかという気持ちが生まれた。
今後ますます分散処理が発展していくといいなぁと思う。