kerasでLeNetを作ります。偉人に経緯を表し、歴史の勉強をさせていただいております。
kerasとは、2022年現在はtensorflowの文法のことです。LeNetとは、FacebookのVice PresidentをされているYann LeCunが1988年末に作ったCNNのことです。このあとLeNetは論文投稿までに何度も改善されていきますが、今回は最も原始的なLeNetを使います。
当時のLeNetの性能は、数字認識に対し、2007枚のテストデータで、acc=95%だったとのことです。
(参考文献)

Table of Contents
インストール
まっさらなLinux環境を用意し、VSCodeと、pipenvをインストールしてあります。
|
1 |
pip install tensorflow-gpu |
実装
お手本にするページは上記の書のこれです。(p59)
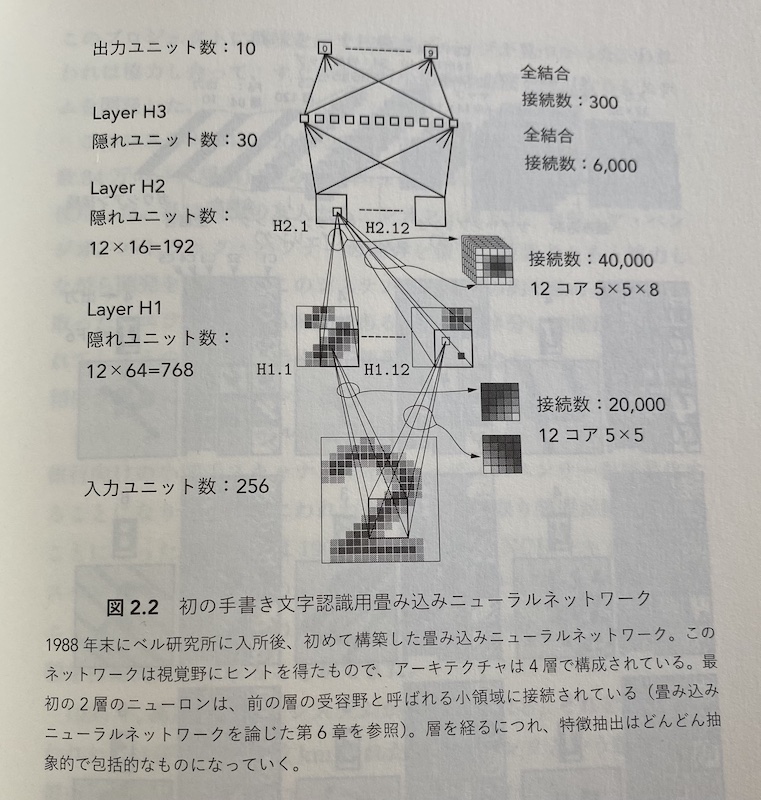
論文も参照しました。
kerasのConv3Dで作ってみるとinput->Layer H1へのパラメーター数が合いません。
本ではパラメーター数20000となっていますが、5×5の畳み込みなので私の実験では416にしかなりませんでした。
その他注意点
- activationはtanhです。
- LossはMSE(Mean Squared Error)です。
- Output LayerはRadial Basis Functionです。
のちほどこれらの理由を考察していきます。
modelのコード
|
1 2 3 4 5 6 7 |
model = Sequential([ Conv2D(16, (5,5), strides=(4,4), activation='tanh', input_shape=(28,28,1)), # Layer H1 Flatten(), Dense(12 * 16), # Layer H2 Dense(30), # Layer H3 Dense(10, activation='softmax') # Output Layer ]) |
model.summary()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 6, 6, 16) 416 flatten (Flatten) (None, 576) 0 dense (Dense) (None, 192) 110784 dense_1 (Dense) (None, 30) 5790 dense_2 (Dense) (None, 10) 310 ================================================================= Total params: 117,300 Trainable params: 117,300 Non-trainable params: 0 _________________________________________________________________ Epoch 1/10 |
コード(full)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D, Dropout, Dense, Flatten, Lambda from keras.backend import argmax, cast from keras.utils import to_categorical from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10) model = Sequential([ Conv2D(16, (5,5), strides=(4,4), activation='tanh', input_shape=(28,28,1)), # Layer H1 Flatten(), Dense(12 * 16), # Layer H2 Dense(30), # Layer H3 Dense(10, activation='softmax') # Output Layer ]) model.summary() model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['accuracy']) model.fit(x_train, y_train, epochs=10, batch_size=16) loss_and_metrics = model.evaluate(x_test, y_test, batch_size=16) |
学習時間計測
|
1 2 |
$ time python src/main.py real 2m42.505s |
でした。GPUは1080iと古めですが、3分で終わります。テストデータでの精度は
|
1 |
accuracy: 0.958 |
でした。ヤンルカン先生の言った通りであることが再現できました。パチパチパチパチ
なぜ3層なのか?
3層ネットワークであるのは層の数が多いとも思えます。なぜ多いと思うかというと、H3が要らないように思えるからです。ためしにH3を消してみましょう。
|
1 2 3 4 5 6 7 |
model = Sequential([ Conv2D(16, (5,5), strides=(4,4), activation='tanh', input_shape=(28,28,1)), # Layer H1 Flatten(), Dense(12 * 16), # Layer H2 # (Comment Out) Dense(30), # Layer H3 Dense(10, activation='softmax') # Output Layer ]) |
テストデータに対する精度は上がりました。
|
1 |
accuracy: 0.9618 |
もしかしたらH2をさらに減らす方法もあるかもしれません。
なぜtanhなのか?
ReLUしか知らない現代人の目には奇異に映るかもしれませんが、このモデルの1番のキモはtanhを使っていることです。
このモデルでここが唯一、Differentialかつ非線形なポイントだからです。
試しにここをReLUにしてみると、他に非線形性がないので一切学習できません。テストデータでの精度は
|
1 |
0.110 |
これはチャンスレート(0~9までの数字を適当に言って、偶然あたる確率)と同じ、です。
やはりこのモデルでReLUは線形関数と同じと扱われてしまうようです。
なぜMaxPoolingが無いのか?
LeNet2にはあります。この時点ではありませんでしたが、acc>0.95は実現できています。
なぜMSEなのか?
損失関数をCross Entropyにしても、問題なく学習できます。てか、こっちのほうが収束が速いです。精度は大差ないです。
当時、損失関数としてのCross Entropyが実用的ではなかった可能性があります。
試しにbatch_size=1にしてみると、Cross Entropyの微分は無限大(nan)となりますが、MSEの微分は当然有限の値になりました。
このことから、コンピューター性能が低かった当時はCross Entropyは実用的ではなかった、と推測しています。
なぜRBFなのか?
これもSoftmaxしか知らない現代人の目には奇異に映るかもしれませんが・・・
ヤンルカンはSVMマスターなのです。
この論文の16年後、2004年にはSVMで物体認識する論文を書いています。
ヤンルカンにとって、SVMのデフォルトであるRadial Basis Functionを使うのは当然の選択だったでしょう。
パラメーター探索
当時の性能を再現できたので野暮かなと思い、しておりません。。。怠慢で申し訳ありません。
ひとつわかったのは、当時のセッティングに合わせてbatch_sizeを低くしたほうがうまく行ったということでした。
|
1 |
batch_size=16 |
感想
意外と再現がうまくいきませんでした。各種のパラメーターが、当時のセッティングに合わせた特殊なものなのではないでしょうか。1回学習するのに4日かかるという当時のコンピューター制約の中、試行錯誤には膨大な時間を要したと思われます。
とても勉強になりました。
ピンバック: DeepLearning数字認識3分クッキング - The Big Computing