画像認識AI歴数年のエンジニアによる入門記事です。物体認識について、初期のアルゴリズムから2020年ぐらいのDeep Learningまでカバーしています。
(会社の仕事内容・独自技術・特許は秘密)
※長くなったのでまとめ→モデル一覧(特徴抽出) / モデル一覧(Deep Learning)
※前者は10種類ぐらい、後者は20種類ぐらい紹介しています。
Table of Contents
AIはどうやって画像を認識しているの?
画像には、「ピクセルが集まって物体を表している」という特徴があります。この特徴をうまく活用するのが画像認識AIです。これは当たり前に画像認識を行なっている我々人類にとっては難しい発想なので、もう少し数字で説明してみたいと思います。
数学的には、例えば解像度1920×1080(FullHD)の画像は1920×1080の「行列」です。しかも、カラー画像であればRGBの3色があるので、行列が3つ重なったものです。
機械学習は画像以外の分野でも行列を扱いますが、画像では隣り合うピクセル同士は同じ物体を指している確率が高い、一例を挙げれば似た色である確率が高いと言えます。だから機械学習にとって、画像は特殊な行列であり、その特徴を学習することがキモなのです。
世界初の画像認識AIとは?
本格的に画像認識の研究が始まったのは、コンピューターが画像を扱えるようになってからです。

Marvin Minsky
1966年にはもうMinskyが画像認識の問題を考え始めていたらしいです。
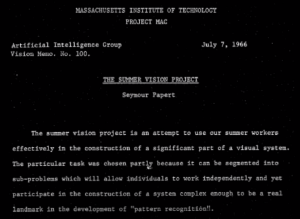
解決に100年を要する見込み
see also: https://www.youtube.com/watch?v=ptcBmEHDWds&list=LL&index=10
当時は人間と同様に画像認識する方法が主に考えられ、
「茶色い長方形の上にある円筒形物体はコップ」
のようなルールベース画像認識の研究が始まりました。色々つっこみどころはありますが、コップの色や形、カメラの撮影角度など、ランダムな要素が多すぎます。このことから、画像認識には「何らかの確率的アルゴリズム」が必要であることが考えられます。またこの方法は、冒頭に述べた「近く同士のピクセルの相関」というアイディアが含まれていないので、当然失敗します。
このような細かすぎるルールの集合ではなく、「物体を表す特徴的な点や、線や、面を認識しよう」という考え方が初期の物体検出アルゴリズムのアプローチでした。
特徴点抽出
「近く同士のピクセルの相関」を捉え、かつ画期的な性能を叩き出した金字塔的なアルゴリズムが1999年(論文は2004年)に発明されたSIFTです。あまりに長く活躍したので、2020年にSIFTの特許が切れたことは大ニュースになりました。
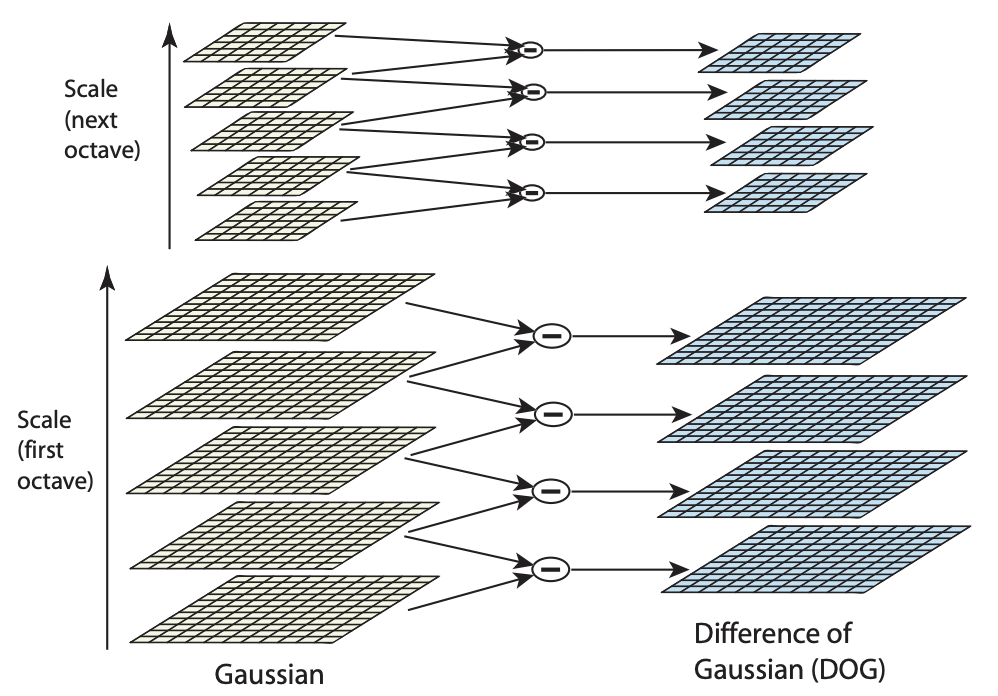
SIFTを理解するために、まず「空間フィルタリング(spatial filtering)」の考え方 – とくにGaussianフィルタの考え方を学ぶ必要があります。各画素について周りの画素を重み付け足し合わせすることをフィルタを適用するとか、畳み込み演算を適用するといいます。どのぐらい広く周囲を見るかをフィルタの大きさといって、3×3フィルタや5×5フィルタ、19×19フィルタなどが考えられます。中心画素自体を含むので、大きさは奇数であることが多いです。この大きさを分散に見立ててGaussianフィルタと呼びます。Gaussianフィルタは画像をぼかすような働きをします。
 I(x+i,y+j) = F*I")
※F=Filter, I=Intensity(ピクセルの色をこう呼ぶことが多い)
SIFTはDifference of Gaussian(DoG)という数学的な仕組みによって、近くのピクセルの類似度を測るものです。これは、分散の大きいGaussianから分散の小さいGaussianを引き算することを意味しています。ぼかした画像からぼかした画像を引く、って意味がわかりませんよね。具体的に考えるとその意味がわかります。例えば本を認識するときに、本の中央と角の例で考えるとわかりやすいです。

- 本の中央では、分散が大きくても小さくても本の表紙の色に変わりはありません。よってDoGを計算すると0になります。
- 本の境界近くでは、分散が小さければGaussianフィルタの結果は本の表紙の色になりますが、分散が大きいと本の表紙の色からずれます。これは、分散が大きい領域に本の外側の色を含むためです。よってDoGを計算すると0ではない値となります。
よって、本の中央のDoGは0、周辺部分のDoGは0でない値になり、区別がつくことがわかります。これが、「近く同士のピクセルの相関を捉える」ということです。この手法は輪郭が多く面積が小さい図形を検出するのに強く、そうした検出はブロブ検出と呼ばれます。
SIFTを皮切りに、無数の特徴点検出アルゴリズムが発明されていきました。フィルタはマイナスの値を許すことで微分(gradient)とも考えられるので、SobelフィルタやHOG(histogram of oriented gradients)のような方法も生まれ、活躍しました。2012年に、このフィルタ構造がConvolutional Neural Networkに受け継がれました。
特徴線(エッジ)検出
点の検出が畳み込みであれば、線の検出は微分演算でした。Sobelフィルタを使ったCanny Edge Detectorがやはりずば抜けた性能と言えるでしょう。

Sobelフィルタは、前述の等方的なGaussianフィルタとは違って、方向性を持ったフィルタです。
![F_x = \left[ \begin{array}{rrr} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{array} \right]\\F_y = \left[ \begin{array}{rrr} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{array} \right]](http://l.wordpress.com/latex.php?zoom=2&latex=F_x%20%3D%20%5Cleft%5B%20%20%20%20%5Cbegin%7Barray%7D%7Brrr%7D%20%20%20%20%20%20-1%20%26%200%20%26%201%20%5C%5C%20%20%20%20%20%20-2%20%26%200%20%26%202%20%5C%5C%20%20%20%20%20%20-1%20%26%200%20%26%201%20%20%20%20%5Cend%7Barray%7D%20%20%5Cright%5D%5C%5CF_y%20%3D%20%5Cleft%5B%20%20%20%20%5Cbegin%7Barray%7D%7Brrr%7D%20%20%20%20%20%20-1%20%26%20-2%20%26%20-1%20%5C%5C%20%20%20%20%20%200%20%26%200%20%26%200%20%5C%5C%20%20%20%20%20%201%20%26%202%20%26%201%20%20%20%20%5Cend%7Barray%7D%20%20%5Cright%5D&bg=FFFFFF&fg=00000&s=0)
![F_x = \left[ \begin{array}{rrr} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{array} \right]\\F_y = \left[ \begin{array}{rrr} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{array} \right]](http://l.wordpress.com/latex.php?latex=F_x%20%3D%20%5Cleft%5B%20%20%20%20%5Cbegin%7Barray%7D%7Brrr%7D%20%20%20%20%20%20-1%20%26amp%3B%200%20%26amp%3B%201%20%5C%5C%20%20%20%20%20%20-2%20%26amp%3B%200%20%26amp%3B%202%20%5C%5C%20%20%20%20%20%20-1%20%26amp%3B%200%20%26amp%3B%201%20%20%20%20%5Cend%7Barray%7D%20%20%5Cright%5D%5C%5CF_y%20%3D%20%5Cleft%5B%20%20%20%20%5Cbegin%7Barray%7D%7Brrr%7D%20%20%20%20%20%20-1%20%26amp%3B%20-2%20%26amp%3B%20-1%20%5C%5C%20%20%20%20%20%200%20%26amp%3B%200%20%26amp%3B%200%20%5C%5C%20%20%20%20%20%201%20%26amp%3B%202%20%26amp%3B%201%20%20%20%20%5Cend%7Barray%7D%20%20%5Cright%5D&bg=FFFFFF&fg=00000&s=0 "F_x = \left[ \begin{array}{rrr} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{array} \right]\\F_y = \left[ \begin{array}{rrr} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{array} \right]")
例えばF_xであれば、右のピクセルから左のピクセルを引いて微分していると解釈することができます。もちろんこれは最適解ではありません。詳しくは後述のCanny Edgeをみてください(クリックしてスクロール)。
他に微分を使ったアルゴリズムとしては、Haar wavelet(ハール特徴)を押さえておくと良いと思います。Haarは私が好きなアルゴリズムで、OpenCV 2.4までは現役でしたが、Deep Learningに負けたという理由で、OpenCV3からはライブラリに含まれなくなってしまいました…
また、ラプラシアンやヘッシアン(ヘッセ行列)といった2次微分を使うことで、エッジが2つ組み合わさったコーナー(角)などを検出できることが知られています。1988年に発明されたハリスコーナーが性能が良いとされています。SIFTの論文でも、ハリスコーナーに大きな影響を受けたということがRelated Researchの章で熱く語られています。
特徴面(領域)検出
点・線ときたら、領域検出です。人間にとっては人(=前景)と背景の分離は簡単ですが、AIから見るとどのピクセルから厳密に前景で、背景なのかがわかりません。
物理学のIsingモデルを応用したGraph Cut, Grab Cutなどが有名です。物理学の拡散方程式を応用したKAZEも面白いです。画像は現実の秩序を2次元に射影したものなので、物理学の手法と密接な関連性があるのです。
風を使わずとも、面を検出できる手法もあります。それが、1999年に提出されたMean Shiftです。
特徴の情報理論・機械学習
点・線・面特徴をみてきましたが、このように全ての画像特徴は近いピクセル同士のなんらかの相関を捉えたものであることがわかります。このことは、確率理論ではエントロピーが低いことを意味します。そこで、FAST(2006年)など、機械学習によって特徴を抽出しようという発想が生まれました。

FASTは、近傍ピクセルの3値化ベクトルに対して、エントロピーを最小化するような境界を決定木で発見することによって、コーナーを発見するものでした。
GrabCutは、前景と背景を分離するために、Isingモデルを使い、統計物理的にエントロピーを最小化しています。
最後に決定的なのがLeCunです。LeCunは物体認識を機械学習で解きました。eigenvectorを活用する方法は、同時期に顔認識でも使われています。eigenvectorは埋め込み表現の一種であり、この時点ですでに表現学習が発明されていました。
paper: Learning Methods for Generic Object Recognition with Invariance to Pose and Lighting
モデル一覧(画像認識機械学習)
いくつかあるので論文の比較・解説を行いたいと思います。(クリックでスクロールします。)
- SIFT
- SURF
- Canny Edge
- Harris Corner
- HOG
- KAZE
- AKAZE
- FAST
- GrabCut
- Mean Shift
SIFT
paper: Distinctive Image Features from Scale-Invariant Keypoints
Loweが1999年に発明したアルゴリズムで、物理的直感にも優れた名著です。SIFTを正しく理解することは人生を豊かにする上でも重要と言えるでしょう。まずはアブストラクトを引用して翻訳します。
画像から、”不変的(invariant)”な特徴点を抽出する方法。特徴点は2枚の画像のマッチングなどに使えます。”不変性”とは、拡大縮小(scale)・回転・アフィン歪み・3D視点の変更・ノイズの追加・照明の変更に対する堅牢性のことです。
SIFT特徴点を使うと、単一の物体を、多くの画像内で高確率で特定できます。SIFTを使った物体認識のワークフローは:
1. fast-ニアレストネイバー(最近傍)を使ったSIFT特徴点の照合
2. Hough変換によるクラスタリング
3. 一貫性のあるポーズパラメータの推定(最小二乗法)この物体認識方法は、clutter(画像の乱れ)やocclusion(隠れ)に強いです。
Abstract of Distinctive Image Features from Scale-Invariant Keypoints
先ほどDifference of Gaussianについて説明しましたが、SIFTはこれを一般化して、1点に対して複数のスケールの複数個数のGaussianをとる=Cascade Filteringというものを起点に考えます。個数は1/logk+3にとります。なぜGaussianが唯一の選択肢なのかというと、それはKoenderink (1984)とLindeberg (1994) という先行研究で証明されていると著者は言います。
もう1つGaussianが優れている点は、DoGがLaplacianに漸近するからです。定義より計算して
 - G(x,y,\sigma)\} * I(x, y)\\\\ \displaystyle\lim_{k\to 1}\{G(x,y,k\sigma) - G(x,y,\sigma)\} = \frac{\partial G}{\partial \sigma^2} \\\\= \frac{\partial}{\partial \sigma^2} \frac{1}{2 \pi \sigma^2} \exp (-\frac{1}{2\sigma^2}(x^2 + y^2)) \\\\= \frac{x^2 + y^2 - 2\sigma^2}{\sigma^4} G = 2 \Delta G")
となります(※原論文とは定数倍違う結果ですが、何度計算してもこうなります…)。これをLoweは「熱拡散方程式が成り立つ」と表現しています。
SIFT特徴点とは、このCascade Filteringを行なった後、その空間内で、「近傍8点+pyramidの隣接層の9点x上下2層」=近傍26点全てより大きい/小さいIntensityを持つ点です。テイラー展開して極値を求め、ヘッシアンを計算してlow contrast点を弾くアプローチが高速とされます。
SIFTの精度検証ですが、人工的に「拡大縮小(scale)・回転・アフィン歪み・3D視点の変更・ノイズの追加・照明の変更+Pre-smoothing」を元画像に行い、同時に特徴点座標の「正解データ」を拡充して、それに対する正答率が80%を超えるかという方法で検証されました。これはまさに、後にDeep Learningで採用されるData Augmentationの方法と全く同じ発想だと言えます。
こうして得たSIFT特徴点からm(勾配強度=magnitude)とθ(勾配方向=orientation)を生成して、SIFT特徴量(SIFT Descriptor)が完成します。最終的にSIFT DescriptorはN(x) x N(y) x N(θ)次元のベクトルとなります。この発想は後述のHOG(Histogram of Gradients)と同様です。
SURF
paper:
Canny Edge
paper: A Computational Approach to Edge Detection
1983年と1986年にCannyが発明したCanny Edge Detectorは引用数34385(2020時点)のものすごい論文で、2002年のAAAIのClassic paper awardです。この論文はSobelフィルタを使ってエッジ検出します。アブストラクトを引用・翻訳します。
エッジポイントの計算に関する「包括的な」目標集合をうまく定義すると、ソリューションに最小限の制約しか課さないにも関わらず、十分厳密なためにいつも検出器が望ましい動作をするようにできます。具体的には、
1. エッジ検出基準(フィルタのインパルス応答の汎関数)
2. 位置特定基準(フィルタのインパルス応答の汎関数)
3. 1つのエッジに対して1つの応答のみを持つようにするための基準です。数値最適化においてこれらの基準を使うといくつかの一般的な画像機能の検出器を導出できます(stepedgeも再現可能)。stepedgeを分析すると、検出と位置特定のパフォーマンスの間にトレードオフがあることがわかります。この原理を、あらゆる状況で満たすようなフィルタ形状は一意に決まります。これには単純な近似実装があり、Gaussianで平滑化した画像の勾配の大きさが極値をとる位置をエッジとみなす方法です。
フィルタの幅を可変に拡張すると、さまざまなSN比(画像にたいするノイズの比率)に対応可能になります。異なるスケール(荒い〜細かい)のフィルタからの情報を統合する、「特徴合成」と名付けた方法を示します。
最後に、等方的なフィルタをエッジ方向に沿って伸ばすとstepedge検出のパフォーマンスが大幅に向上することを示します。各点で複数の細長いフィルタを使用し、その出力が勾配極値検出器と統合されます。
Abstract of A Computational Approach to Edge Detection
ひとことでSobelフィルタとは言えず、非常に複雑な構造を持った手法であることがわかるかと思います。stepedge検出とは何かと言うことが気になるかと思いますが、こういうもののこと(階段関数+ノイズ)です。
2次元画像におけるedgeは特定の1次元断面を取れば上の図のようになるだろうと予想して、1次元の問題を考えます。まずSobelフィルタ(の1次元版=-1,0,+1)を上のような波に適用すると、最大値としてエッジが検出できます。
次に、Sobelフィルタが属する函数空間から、3つの汎関数(関数→実数への写像)を用いて関数検索を実行して、最適な関数を見つけます。
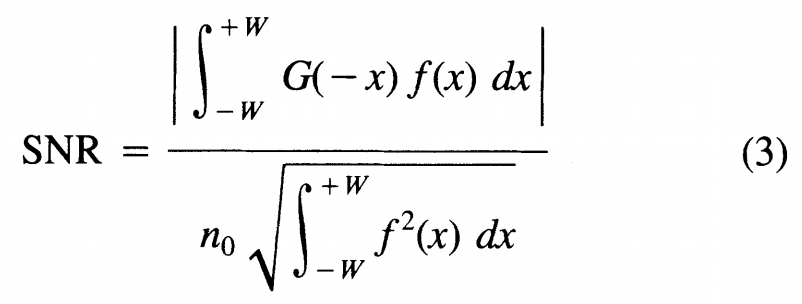
この汎関数はシュワルツの不等式で上界が簡単にわかるのがemoいですね。
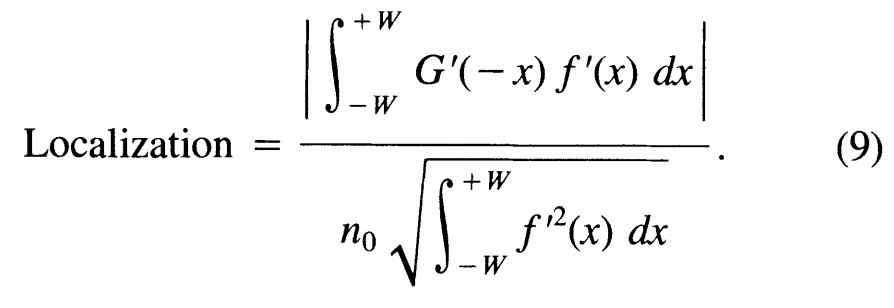
最後が、極値と極値の間隔の最大化です。
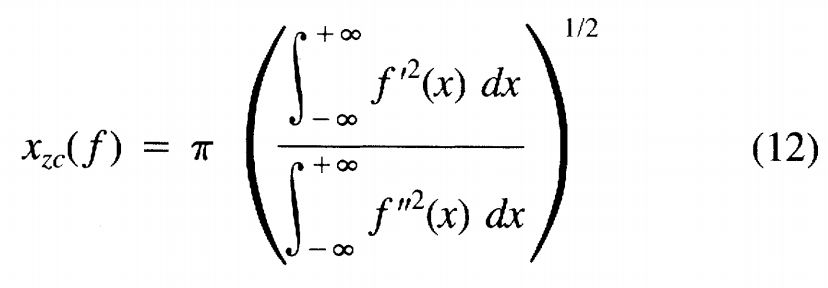
つまりアブストラクトにある3つの最大化すべき汎関数はf / f’ / f”で書けると言うことがわかりました。これらの汎関数をテイラー展開して、fをフーリエ変換してフーリエ係数について拘束式を展開し、フーリエ係数の空間を探索します。
Canny Edge Detectorの高性能の根拠は、こうした関数空間探索にあるわけですね。
Harris Corner
paper:
HOG(Histogram of Gradients)
paper: HOG: Histograms of Oriented Gradients for Human Detection
CVPR 2005なのでSIFTの論文が出た翌年ですね。
結論から言うと、HOG DescriptorはN(x) x N(y) x N(θ) x 2 x Block(cellを含むblock数)の長さのベクトルになります。Blockと言う概念は、cellの集合体であり、正規化に使われる単位です。
KAZE / AKAZE
paper: KAZE Features
熱拡散方程式に補正項を加えたアルゴリズムです。日本人のIijima先生への敬意から日本語で風という命名がされたアルゴリズムです。熱拡散のイメージより、風による拡散のイメージがぴったりくるアルゴリズムです。アブストラクトを引用・翻訳します。
KAZEは2Dにおける特徴検出です。非線形スケール空間でも動作します。
これまでのアプローチは、Gaussianフィルタを様々なスケールで作成し近似することで、特徴を検出していました。しかしぼかし(blurring)はオブジェクト境界そのものを考慮せず、ディテールとノイズの両方を同程度に平滑化するため、位置特定精度と識別性が低下します。
KAZEは非線形な拡散フィルタリングにより特徴を検出します。この方法は局所的にぼかし(blurring)を適用し、ノイズを低減し、オブジェクト境界を保持し、優れた位置特定精度と識別性を得られます。
非線形スケール空間は、効率的な加法演算子分割(AOS)技術と可変伝達拡散を使用して構築されます。
十分なデータセットにおける評価とユースケースを紹介します。
非線形スケール空間の構築コストはSURF以上SIFTと同程度で、検出精度はSOTAです。
Abstract of KAZE Features
伝達係数(conductivity efficient)の定義をみてみましょう。

FAST
paper: Machine Learning for High-Speed Corner Detection
GrabCut
paper: “GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts
説明の順序ではここにきてしまいましたが、siggraph2004なのでそれなりに古典です。Microsoft Research発ですね。これがどんなものかと言うと、photoshopのマジックワンド使ったことありますか?同じような色を単一領域として自動選択してくれるツール。あれです。名前の由来ですが、”grab”というのはドラッグして矩形領域を選択する方法のことで、長方形を作るだけで前景抽出されることを意味します。あと先行手法のgraph-cutとのシャレです。

アブストラクトを引用・翻訳します。
画像編集における重要問題として、画像を効率的かつインタラクティブに前景/背景分離(セグメンテーション)する問題があります。従来のセグメンテーションツールは、テクスチャ情報か色情報を利用します。これらのツールにはマジックワンドやインテリジェントはさみがあります。
graph-cutは両方のタイプの情報をうまく組み合わせる手法ですが、我々はgraph-cutを3つの点で拡張します。
1. 最適化を改善し反復するようにした。
2. 必要なユーザーへの問いかけが大幅に減った。
3. 境界推定が安定化し、オブジェクト境界の周囲のアルファチャンネルと前景ピクセル色を同時に推定可能になった。今まで難しいとされていた画像に対しても、GrabCutは競合ツールより優れています。
Abstract of “GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts
Mean Shift
paper: Mean Shift Analysis and Applications

ひとやすみ(ここまでのまとめ)
ここまで長かったと思います。お疲れ様です。ここまで(2009年ぐらいまで)の考え方を要約します。
- 細かすぎるルールベースは機能しない
- 点・線・面などを微分に基づいて検出する
- あらゆる画像に存在する秩序を扱っているため、特徴抽出は必然的に教師なし学習である(重要な伏線)
- 抽出した特徴に対し、教師あり学習、例えばDecision TreeやSVMを行うことによって物体認識精度を上げていた。
畳み込みニューラルネットワークとは?
Deep Learning=Deep Neural Network=DNNとは、「深い(8以上の)層を持つニューラルネットワーク」です。CNN(Convolutional Neural Network・畳み込みニューラルネットワーク)はDNNの一種で、自由度を制限したものです。
CNNは上記のフィルタ重み自体を変数として学習可能にしています。CNNではフィルタをカーネルと呼びます。
また、Deep Learningでうまくいくことを理解するために、Image Pyramidを説明します。Image Pyramidとは…
DoGもImage Pyramidとして解釈できるため、Deep Learningを使えば、DoGのような特徴抽出を再現でき、それを超える特徴を学習できると推測できます。実際にCNNの中間層の出力とSIFT特徴量の性能を検証した論文が、以下の論文です。(Flownetの作者です)
paper: Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
アブストラクトを引用・翻訳しますが、特に最後に注目してください。
教師なし学習は、DNNが教師あり学習で達成したような性能を出せていません。しかし教師あり学習は特定のタスクのみで高精度であり、今回は教師なし学習で一般的な特徴量を発見することを目指します。
具体的には、一連のサロゲート(代理・人工)クラスを区別するようにネットワークをトレーニングします。各サロゲートクラスは、ランダムサンプリングした「シード」画像にさまざまな変換を適用して生成します。教師あり学習と異なり、結果の特徴表現はクラス固有ではなく一般的で、一連の変換に対して堅牢でもあります。いくつかのデータセット(STL-10、CIFAR-10、Caltech-101、Caltech-256)の教師なし学習で、分類のSOTAです。
得られた一般的特徴量は、タスクを固定した教師あり学習には敵いませんが、SIFTを使ったマッチング性能を上回ります。
Abstract of Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
個人的には素直な理論的興味として好きですが、引用数が401(2020年時点)に留まっており、Deep Learningの進化が早すぎる昨今、こうした理論的研究には光が当たりづらいのかもしれません…。
ネオコグニトロン
世界初のCNNは1980年のNeocognitron(ネオコグニトロン)と言われています。引用数も4000を超えており、日本の誇るべき論文です。ただ、この論文には教師あり学習のトレーニングアルゴリズムが無く、特徴抽出のみができるだけなので、特徴抽出の視点ではSIFTより本当に優れているとは言い難いのではないか?と思います。
モデル一覧(Deep Learning)
いくつかあるので論文の比較・解説を行いたいと思います。(クリックでスクロールします。ブラウザの戻るボタンで戻ります。)
- alexnet
- VGG
- Auto Encoder
- Denoising Auto Encoder
- Restricted Boltzmann Machine
- R-CNN
- Fast R-CNN
- Faster R-CNN
- YOLO
- resnet(skip + repeat)
- DenseNet
- Fully Connected Network
- UNet
- Mask R-CNN
- PSPNet
- mobilenet
- mobilenetv2(separable convolution)
- Variational Auto Encoder
- Xception(resnet + separableの融合)
- SE-Net
- NAS(Neural Architecture Search)
Alexnet
paper(NIPS): ImageNet Classification with Deep Convolutional Neural Networks
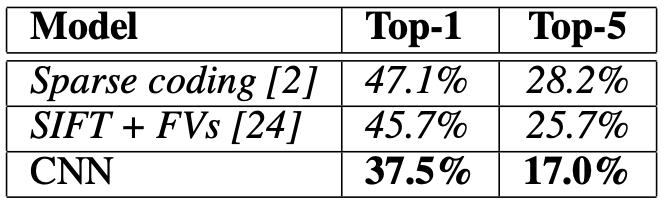
最初にDeep Convolutional Neural Network(8層)を採用して大きな成果を挙げたのがAlexnetです。2012年、著者はAlexとSutskeverとHintonです。特に後者2人は神です。アブストラクトを引用・翻訳しますが、この文の中でも精度に注目してください。前年の2011年に優勝したXRCE(by Xerox)のトップ5エラー率=26.0%です。
ImageNet LSVRC-2010コンテスト(120万枚の画像を1000の異なるクラスに分類)において、大規模なDeep Neural Networkをトレーニングしました。テストデータでは、トップ1のエラー率=37.5%とトップ5のエラー率=17.0%を達成しました。これはSOTAです。
このDNNは6000万パラメーターと65万ノードのニューロンを持ち、5つの畳み込み層を持ち、マックスプーリング層を持ち、最後に1000出力のソフトマックスを持つ3層のFully Connected Layerがあります。
高速化のためにReLUとGPUを採用しました。オーバーフィッティングを避けるために正則化手法であるDropOutを採用しました。
ILSVRC-2012コンテストにおいて、このモデルのバリアントはTop5エラー率=15.3%を達成し優勝可能でした。(2位=26.2%)
Abstract of ImageNet Classification with Deep Convolutional Neural Networks
なぜ彼らは世界で最初にDeep Learningで世界一を獲れたのでしょうか?

まず1つめに、先行研究との差はデータセットの差でした。当時のMNIST(手書き数字データセット)に対するエラー率は0.3%未満でした。しかし、これは現実世界の物体認識とはかなり遠い問題設定であり、理論の深化を妨げていました。MNISTはつまり2012年の画像認識の発展した世界においては簡単すぎる問題であり、Deep Learningはそのぬるま湯からは生まれなかったのです。ImageNetという困難な問題の出現(2009, CVPR)とともにAlexNetの種は生まれたのです。ImageNetの作成を可能にしたのはAmazonのMechanical Turkです。クラウドソーシングツールが世界を変えたのでした。
第二に、すでにCNNが発明されていたことです。ReLUもDropoutもHintonが発明済みでした。Back PropagationもHintonが有名な論文を書いて再発見済みでした。Data Augmentationも当時すでに誰かが発明済みでした(少なくとも1999年のSIFTでも利用されているためその時点で発明済みである)。
Back PropagationのHintonの論文はこれです。
paper: Learning representations by back-propagating errors
DropOutの、Hinton+Alex+Sutskever+Srivastava+Salakhutdinovの論文はこれです。
paper: Improving neural networks by preventing co-adaptation of feature detectors
AlexNetの欠点は、
- ハイパーパラメーターが多く、画像セットに依存する。(k, n, α, β, …)
- 畳み込みカーネルの不必要な大きさ。11×11および5×5が存在する。
- ネットワークの層が浅く8層にとどまる。これは当時のGPUの限界
- ただし、7層にするとがくっと性能が下がることを証明し、Deep化への不可逆的な方向を決定づけたのは功績。
なにはともあれ、AlexNetの登場によってSIFTは王座を受け渡すことになったのでした。
VGG: Visual Geometry Group
paper: VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
最初に「Very Deep」なネットワークを作り大きな成果を挙げたのがVGGです。2014年、著者はKaren SimonyanとAndrew Zissermanです。
AlexNetに比べ、Top5errorは17.0%→6.8%となりました。93.2%も正解しているわけです。人間の能力に肉薄してきましたね。
VGG-19のネットワーク構造を引用します。conv3は3×3カーネルによるConvolutionです。AlexNetはConv*5層+FC*3層ですが、VGG-19はConv*16層+FC*3層です。
| conv3-64 |
| conv3-64 |
| maxpool |
| conv3-128 |
| conv3-128 |
| maxpool |
| conv3-256 |
| conv3-256 |
| conv3-256 |
| conv3-256 |
| maxpool |
| conv3-512 |
| conv3-512 |
| conv3-512 |
| conv3-512 |
| maxpool |
| conv3-512 |
| conv3-512 |
| conv3-512 |
| conv3-512 |
| maxpool |
| FC-4096 |
| FC-4096 |
| FC-1000 |
| softmax |
…深い!!!
この手法のキモは、3×3フィルタという極小フィルタのみを利用しながら、層を深くすることで精度を挙げたことです。先行研究では、5×5のフィルタが使われたり、11×11のフィルタが使われたりしていて、strideという変数もあり、モデルの自由度が高すぎました。VGGの成果によって、オッカムの剃刀的に、そこに不必要な自由度を持ち込む必要がないことが証明されたのは大きな成果であると言えます。
Auto Encoder
paper: Reducing the Dimensionality of Data with Neural Networks
でも、そもそも
なぜカーネルを使って画像を小さくしていくと、物体認識ができるのでしょうか?
AlexNetにも関わったHintonはすでに2006年にあるものを再発見していました。Auto Encoderです。
AutoEncoderとは、小さな中間層を持つニューラルネットワークのことで、Hour-glass(砂時計)型のネットワークとも呼ばれます。
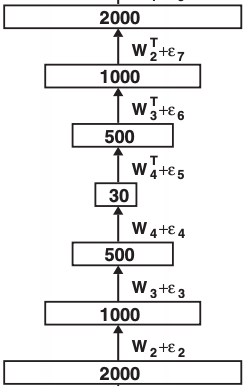
入力〜中間層までをエンコーダーと呼びます。この部分は画像を行列ではなく数千次元のベクトルととらえ、ベクトルの次元を圧縮する働きをします。
中間層〜出力までをデコーダーと呼びます。この部分は低次元ベクトルから高次元ベクトルを復元します。
AutoEncoderは、入力画像と全く同じ画像を復元するように学習します。Autoとは、自己復元性を意味するわけですね。ということは、低次元ベクトルに、出力画像を再構成するのに必要な情報が全て含まれているということを意味します。これが次元圧縮です。
Hintonの論文のアブストラクトを引用・翻訳します。
高次元データは、小さな中央層を持つDNNをトレーニングして高次元入力ベクトルを再構築するAutoEncoderで、低次元に圧縮できます。
AutoEncoderをSGDで学習することができるのは初期のウェイトが解に近い場合のみです。AutoEncoderは次元圧縮のツールとして主成分分析よりも優れていますが、より効果的なウェイトの初期化法を説明します。
Abstract of Reducing the Dimensionality of Data with Neural Networks
この次元圧縮により、画像の本質的な情報だけが抽出されるために、カーネルで画像を小さくすることで物体認識ができるのです。
冒頭の図をもう一度見てみましょう。これは、中間層を2次元にし、2次元に情報を圧縮した結果の図です。きちんと、本質的なカテゴリ情報がエンコーディングされていることがわかります。
もうひとつの動きがBengioの特徴抽出です。
Denoising AutoEncoder
paper: Extracting and Composing Robust Features with Denoising Autoencoders
2009年にBengioが発明したDenoising Auto Encoderは、ノイズを加えた入力からノイズを加える前の入力を再構築するよう学習するものです。
これにより、ノイズという非本質的な情報を捨てながら、本質的な情報のみをエンコードすることができるようになります。
しかし、これはAlexNet登場以前であり、SIFTなどの手法に精度は遠く及びませんでした。
Restricted Boltzmann Machine
ところで、AutoEncoderの論文を読まれた方はRestricted Boltzmann Machine(RBM)という単語が出てきたことに気づかれたでしょうか?
paper: Dimension Reduction by Local Principal Component Analysis
RBMは1997年にKambhatlaとLeenによって発明されました。
Boltzmannは統計物理学の父であり、歴史上初めて「エントロピー増大則」に気づいた人物です。Boltzmann Machineは統計物理学のIsing Modelを使って機械学習する仕組みです。
Restricted Boltzmann Machineは、Boltzmann Machineの一種で、コネクションに制限を加えたものとなります。vとhはvisible(見える)/hidden(隠れている)の略で、vが画像に、hがAutoEncoderの中間層に対応しています。vとhの結合のみが許されています(restricted)。
 =\\\\ \displaystyle - \sum_{i \in pixels} b_i v_i - \sum_{j \in features} b_j h_j - \sum_{i, j} w_{ij} v_i h_j")
こうしてRBMは、3層のAutoEncoderであると見做すことができるわけです。
RCNN: Regions with Convolutional Neural Networks
paper: Rich feature hierarchies for accurate object detection and semantic segmentation
CNNによって物体の大きさまで検出できるようになったものがRCNNです。2013年、著者はRoss Girshickです。
モデルとしてはおそろしく単純で、
- Region Proposalを実行
- 各RegionをAlexNetに入れる
だけです。この手法のキモは、画面全体から長方形領域を作成し、それらすべてに「物体である確率」を計算することなわけです。しかしながら、AlexNetを実行する回数が多すぎて低速です。
Fast R-CNN
paper: Fast R-CNN
では、如何にCNNを呼ぶ回数を減らすか?
Fast R-CNNはselective searchによって全ての矩形を評価するのでは無く、効率的に探索を可能にしました。このアルゴリズムの原型になった、Cascade Classifier(Haarフィルタとsliding windowとexhaustive search)についても勉強しておくと理解がしやすいです。
paper: Selective Search for Object Recognition
selective searchについてはこちらの記事もみてください。
Faster R-CNN
paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNNは、Kaiming HeとRoss Girshickが組んだ2015年の論文です。
Faster R-CNNはRegion Proposal Networkの追加により、End-to-End学習を可能にしたためCNNをなんども評価する必要がなく、高速となりました。RPNは長方形の集合を出力します。
YOLO: You Look Only Once
paper: You Only Look Once: Unified, Real-Time Object Detection
長方形の総当たりではなく、長方形の座標を回帰で予測するというアイディアがYOLOです。確かに、このメカニズムは人間の認識方法に近い気がします。2015年、著者はJoseph Redmonです。
R-CNN族は単純な発想ながら、着実に性能を上げていきました。1秒間に何枚の画像を処理できるかという数字を、FPS(Frames per seconds)と言います。FPSが大きければ大きいほど速いわけです。R-CNNの性能はこんな感じで増えていきました。
- R-CNN FPS=0.01~0.09(遅い)
- Fast R-CNN FPS=0.5(2秒待てば終わるので耐えられなくはない)
- Faster R-CNN FPS=7(0.14秒)
R-CNN族は、地道にしかし着実に、VGGが「画像を見る回数」を減らしていったのです。そんな時に、YOLOは青天の霹靂のごとく現れました。
「人間は1回しか見ねぇだろ?」
「You Only Look Once?」
そう、R-CNNの理論によれば、1回しかVGGを評価しないのが最速なのです。そしてYOLOは、突然それを成し遂げました。YOLOの速さは以下の通りでした。
- YOLO FPS=45
- Fast YOLO FPS=155
・・・もはや勝敗は明らかでした。
YOLOのアイディアは、一回の回帰を実行することで、長方形座標を複数生成してしまうことにあります。そして、各長方形がClass Probability Mapに結合(長方形内部のクラス数を数える)されます。つまりこのネットワークの出力はかなり変則的で、5(x,y,w,h,confidence) * N(長方形候補数) + 7 * 7(フィルタにより画像を448×448→7×7=縦横1/64に縮小) * C(クラス数)なのです。

Regression
その結果、もっともconfidenceが高い長方形と、その長方形が表すクラスの組み(x,y,w,h,c,confidence)が出力され、物体検出ができます。
Redmonは自分のフレームワークをdarknetと呼び、中二病罹患患者として一躍有名になりました。またYOLO9000という名前もHAL9000から来ていて中二病です。ちなみに私の本名の由来もHAL9000です。

Resnet: Residual Net
paper: Deep Residual Learning for Image Recognition
この論文は、CVPRで2020年4月時点だと25256回と最も引用された伝説の論文です。
先行研究であるVGGが19層なのに対し、ResNetは152層です。
Resnetは史上初めてresidual、つまり回帰における残差を予測することを思いついたアプローチです。2015年、著者はKaiming Heらです。これを理解するにはAutoEncoderを理解しておく必要があります。残差を実現する方法として、short-cut connectionが発明されましたが、これはのちの時代のネットワークでなんども使われていく大発明となりました。
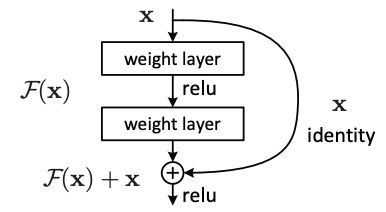
この手法のキモは、AutoEncoderにおけるEncode領域を、repetitionと呼ばれる6層xN回の領域に渡って残差を最小化し続ける部分です。この部分がモデルの表現力に直結します。
short-cutのみに気をとられがちですが、repetitionもResNetでは重要な構造です。AutoEncoderを思い出してみるとわかりますが、層を深くするということは、次元圧縮に使える空間がどんどん低次元担っていくことを意味し、表現力が損なわれていくため限界がありました。しかし、ResNetにおけるresidual blockは入力と出力で次元数が変わらず、repetitionを繰り返しても次元数が変わりません。ResNetは固定された次元でrepetitionの回数を増やすことで、豊かな表現力を実現しているため、精度が高いのです。
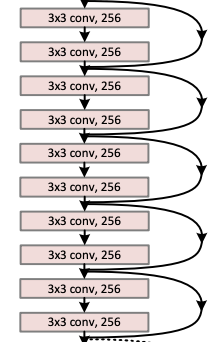

先行研究でこのrepetition構造がとれなかったのは、層が深くなるほどパラメーター空間の次元が上がることによる勾配消失問題の影響が大きくなるからです。ResNetはshort-cutを導入することで勾配消失問題を避けることができました。そのため、今まで禁じ手であった、repetition構造をとっても動くようになったわけです。
とはいえ、repetitionには最適回数があります。それを調べようというモチベーションで実験した記事がこちらです。
ResNetの欠点としてはDropoutできないことです。このことは、ネットワークがSparseになっていることからもわかります。1つのコネクションがノックアウトされるだけで致命傷になるからです。しかし、この論文以降、割り切ってDropoutを完全に排除してSparseなネットワークを使う研究が増えた気がします(私見です)。
FCN(Fully Convolutional Network)
paper: Fully Convolutional Networks for Semantic Segmentation
RPNはピクセル単位のクラス予測を必要とし、同一クラスのピクセルが連結していないとおかしなことになります。そのため高難度のタスクでした。これも2015年の論文ですが、こちらの方が崇高な思想に基づいています。
この手法のキモは、「再現解像度」を変えた複数の出力を用意し、例えば人のセグメントを求めるとき低解像度のもの(FCN-32sと呼ばれる)はぼんやりとした人影を、高解像度のもの(FCN-8s)は人影の詳細な輪郭を予測させマージするという点です。
先行研究との比較だと、U-net構造を使っているため、U-netについても理解しておく必要があります。
U-Net
paper: U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Netの問題意識は、encoder-decoder構造だと情報損失が起こるために、輪郭情報を捉えられないということです。U-Netは、もともと生物分野で、細胞の顕微鏡写真において細胞壁を抽出するタスクの問題意識から生まれました。
そこで、著者らは輪郭情報を入力イメージから持ってくることを思いつきました。
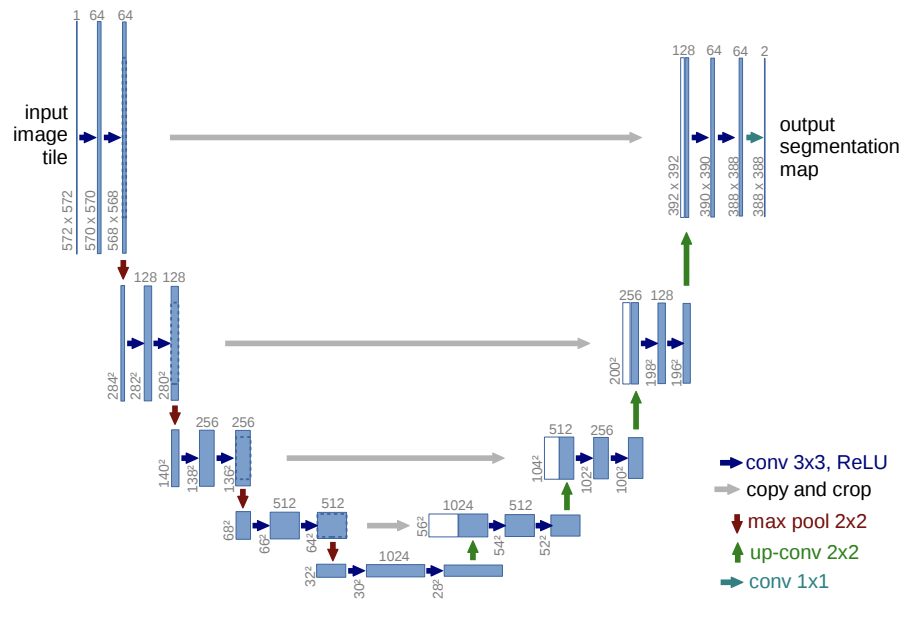
この図において、一番下の層が、情報が最もencodeされていることを表しています。
Mask R-CNN
paper: Mask R-CNN
Kaiming HeとRoss Girshickは改善を重ね、ICCV2017で、RCNNも進化した。Region Proposal Networkが、Fully Convolutional Networkに置きかわり、Mask R-CNNとなったのだ。Maskは、1ピクセルごとにどのクラスに属するかを予測する。
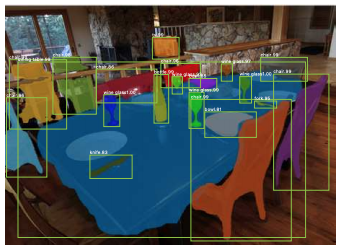
MobileNet
paper: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
アブストラクトを引用して翻訳します。
モバイルおよび組み込み用のモデルMobileNetsは、通常の畳み込みをseparable convolutionにして軽量化します。
モデルサイズをコントロールする2つのハイパーパラメーターがあり、latencyとaccuracyがトレードオフになります。
ImageNet分類タスクで圧倒的性能が出ます。他のユースケースには、物体検出・fine-grained分類・顔認識・地理位置特定があります。
Abstract of MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
モデルは複雑化していき、論文ごとに改善しているとはいえ、まだまだ遅いままでした。MobileNetは2017年に、スマートフォン上でDeep Neural Networkを動作させることを目的に作られました。スマートフォンの制約はメモリの少なさです。パラメーター数が数億のDeep Neural Networkだと、メモリをギガバイト近く消費してしまうのです。なので、いかにパラメーター数を減らす(=痩せさせる)かが勝負になります。
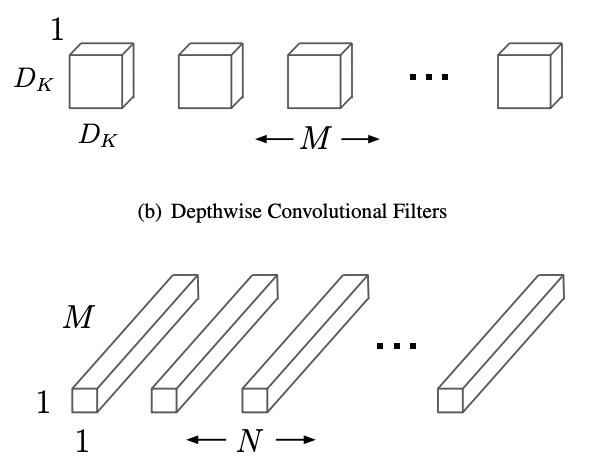
この手法のキモは、Convolutionを行列分解することで、パラメーター数を痩せさせることです。これは、元のconvolution層を、Depthwise層とPointwise層の組み合わせによってパラメーター数を減らしたまま再現しようと言う試みです。全ての行列分解と同様に、この方法では任意の行列を再現できるわけではありません。これにより、モデルの表現力が失われる原因になりましたが、convolutionの学習が高速化したことになり、これ以降の研究は進化スピードの向上の恩恵にあずかることになりました。
私見ですが、これによりDeep Learning研究がConvolutionを脱し、より本質的なことに注力するきっかけになったのではないでしょうか。
DenseNet
paper: Densely Connected Convolutional Networks
2016年に、ResNetを大胆に改善する方法が提唱されました。CVPR 2017のBest Paper Awardのすごい論文です。DenseNetでは、Skip Connectionが、直前のBottleneck層からだけではなく、全てのBottleneck層から張られるようになりました。言葉で書くと難しいですが、絵にすると次のようになります。
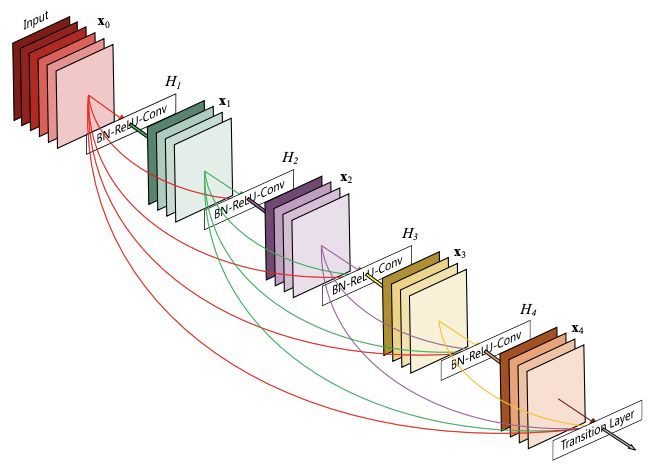
XceptionNet
paper: Xception: Deep Learning with Depthwise Separable Convolutions
kerasの著者のFrançois Cholletが2017年に提唱したネットワークです。この手法のキモは、行列分解とshort-cut connectionの両方を使うところです。
MobileNetv2
paper: MobileNetV2: Inverted Residuals and Linear Bottlenecks
Inverted Bottleneckの発明により、mobile-netの精度を向上した2019年の論文です。
先行研究(MobileNet/Resnet)との違いは、通常のresnetと異なり、次元圧縮をした層(Bottleneck)同士にshort-cut connectionを入れることです。なぜこうするかというと、低次元空間のほうが、元の高次元空間よりも容易に残差=ゼロを学習できるためです。
この手法のキモは、3つの工夫を組み合わせたところです。
- Deep Separable Convolution
- depthwize / dwize
- pointwize / pwize
- Bottleneck Convolution
- Bottleneck Residual Block
これらを組み合わせたものが、Bottleneck Depth Separable Convolutionと呼ばれます。
(2018年10月にarXivで見たときは引用数48だったが、2020年4月には1593であった。)
Variational Auto Encoder
paper: Auto-Encoding Variational Bayes
全く違う発想をしていたのが、Kingmaです。
SE-Net
paper: Squeeze-and-Excitation Networks
NASNet
paper: Learning Transferable Architectures for Scalable Image Recognition
CNNはFully Connected Networkにおいて特定のパラメーターを0にしたものですが天下り的です。本当に0にしなければならないパラメーターは、探索によって見つけるべきものなのではないでしょうか?
YOLOv3
圧倒的な工夫と圧倒的な性能(執筆中)
EfficientNet
圧倒的な速度(執筆中)
時系列まとめ
クリックでスクロールします。
- 1980 ネオコグニトロン
- 1986 Canny Edge
- 1988 ハリスコーナー
- 1999 SIFT
- 2004 GrabCut
- 2005 HOG+SVMによる人間の認識
- 2006 FAST
- 2006 Auto Encoder(Hinton)
- 2009 De-noising Auto Encoder(Bengio)
- 2012 KAZE
- 2012 AlexNet
必要な数学まとめ
敷居が高くなるので最初には書きませんでしたが、ここまでの画像理論を理解するために、以下の数学分野が登場しました。学部1~2年のうちに押さえておきましょう。
- 微分積分…損失関数の最適化に微分、確率演算に積分。
- 線形代数…機械学習は行列演算。次元圧縮。最適化の反復法。
- フーリエ解析…確率論の特性関数や中心極限定理。
- ルベーグ積分…機械学習の問題に正しく確率空間を定義する。
- 確率論…コルモゴロフの公理系に従って正しく理解する。
- 偏微分方程式…偏微分方程式から導かれる特徴など。
- 関数解析…L2空間が頻出。関数空間内の点列収束など。
- 微分幾何…機械学習のパラメータ空間の幾何学を理解するため。
- 代数幾何…確率モデルにおけるブローアップを理解するため。
偉人まとめ
Geoffrey E Hinton
1947年生まれ。初期は冷ややかな視線を浴びつつも、ニューラルネットワークの可能性を信じて論文を書き続け、世界一のDNN科学者となった。
人間がどのように世界を認識しているかにこだわり続けていて、その思想はCapsule Networkに結実する。
Yang LeCun
LeCunも古い時代から物体認識の分野で活躍しており、物理的な考察が光る論文を多数残している。そのキャリアはLeNetに結実する。
Joshua Bengio
Diederik P Kingma
Ross Girshick
Joseph Redmon
C言語でdarknetというオープンソースを開発した。
2020年にComputer Visionを引退した。
彼の後は、darknetのメンテナーが引き継いだ。
Kaiming He
オープンソースを使う方法
OpenCV
OpenCVを使えば、多くのアルゴリズムを自分で試すことができます。
keras
Keras Applicationsを使えば、多くのDeep Neural Networkを自分で試すことができます。
papers with code
papers with codeを使えば、第三者による独自実装を自分で試すことができます。(信頼性は上2つに比べて大きく下がります)
オススメの書籍





あたりが候補だと思います。個別に解説してみます。
画像認識
これは、古典的なHand-crafted特徴量について特に詳しい本です。なぜDeep Learningで画像認識がうまくいくのか?という根本的な問いを抱えている方にとっては、格好の指南書になるでしょう。
しかし、出版年月(2017年)の関係で、Deep LearningについてはFaster R-CNNや、ResNetまでしか書いていないのが難点です。
深層学習
2016年なので古いのですが、原理的には重要な制限ボルツマンマシンと、CD方法、深層ベイズなどが乗っているのはポイント高いです。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
いい本ですよね。私も3冊持ってます(なぜか)。しかし、著者が自然言語解析系の人なのか、画像については記述があまりありません。残念です。
深層学習(アスキードワンゴ)
GANを発明したGoodfellowが書いた分厚い本です。尊敬してます。尊敬していますよ。こんなに分厚い本を翻訳した翻訳者の方々も偉いと思います。
でも、すみません、つまらないんです!!!各論の記述があまりにも浅すぎます。Goodfellowには3倍ぐらいの分厚さで本書を改定して欲しい、そうしたらPRMLを超えるかもしれないと半ば本気で考えています。
機械学習スタートアップシリーズ これならわかる深層学習入門
どうせ論文たくさん読むことになるので、書籍はできるだけ簡単なものの方がいいです。
実戦深層学習
とはいえ、ここまでの知識は深層学習の仕事の実戦には少し心もとない程度に過ぎません。何より、Topカンファレンスに限っても、画像の論文は毎年恐ろしい量が生み出されているのです。
- NIPS 約5000
- ICML 未調査
- ICLR 約1500
- CVPR 約5000
- ECCV 未調査
- ICCV 未調査
- SIGGRAPH 未調査
学会に行って古い理論から新しい理論まで全てをリスペクトして吸収する姿勢と、原理を理解することによって体力をつけるのが良いと思います。
ピンバック: 読んだ:MobileNetV2: Inverted Residuals and Linear Bottlenecks (arXiv : 2018) | The Big Computing
ピンバック: 読んだ: HOG: Histograms of Oriented Gradients for Human Detection; CVPR 2005 | The Big Computing
ピンバック: ResNet20~ResNet152:shortcutのResNet多層化への影響 | The Big Computing
ピンバック: 読んだ: Selective Search for Object Recognition; IJCV, 2013 | The Big Computing
ピンバック: スパイラル・ラーニング 技術者の四季と螺旋 | The Big Computing
ピンバック: データサイエンス人気記事 - The Big Computing