根本的な疑問
ResNetのshortcut(short circuit)は層をディープに(152とか)するためのものだが、ふと浅くしたらどうなるのだろうと思った。浅くしたら、resnetの理論の証明が可視化できるのではと。この疑問はshortcutのResNet多層化への影響、と言い換えても良いかもしれない。
(ResNetとは?はこちらの記事をお読みください)
ResNetの層の数は6n+2で表される。最小は理論上8で、ResNet8・ResNet20などが最も小さいものとして考えられ、よく使われるのはResNet34・ResNet50・ResNet104・ResNet152である。
科学的に考えると、極力層の数以外を同等にした実験条件を作らなければならない。試行錯誤の上、以下のような実験条件を考案した。
- ネットワークは「相似かつ細部が合同」であるようにする。
- input layerは同じ。
- output layerも同じ。
- Activation/BatchNormalization/Dropout(resnetは利用しない)/Poolingもすべて同じ。
- 途中層で「次元圧縮する速さ」だけを3倍(=6層かかるところを2層にする)にし、resnet20からresnet8-pyramidと呼ぶネットワークを作る。
- 学習方法を統一する。
- 学習データとバッチサイズは同じ。(どちらもCipher10/32)
- TODO: データオーギュメンテーションを同じにする
- これは実験後に気づいたため未実装だが、8と8、20と20では同じオーギュメンテーションになるようになっているので大丈夫だろう
- ウェイトの初期化に使う確率分布は同じ。
- lr_schedulerは同じ。
- SGDのパラメーターも同じ。(momentum=0.9)
- 両者ネステロフを使っているが影響は不明
なぜ今resnetなのか?
resnetは宇宙の真理を表している。これは、resnetの仕組みが出版後5年のほとんどのネットワークで利用されていることからもわかる。resnetは今もこれからも永遠に残るのだ。特に、次元圧縮と組み合わせたMobileNetV2の論文は感涙モノであり、マジで布教したい。
比較対象
- 普通のresnet、resnet20。accuracy=91%いくことを確認済み。
- resnet20からショートサーキットを除去したもの(simple_conv_net20と呼ぶことにする)
- 最も浅いresnet(たぶん)、resnet8_pyramid
- resnet8_pyramidからショートサーキットを除去したもの(simple_conv_net8と呼ぶことにする)
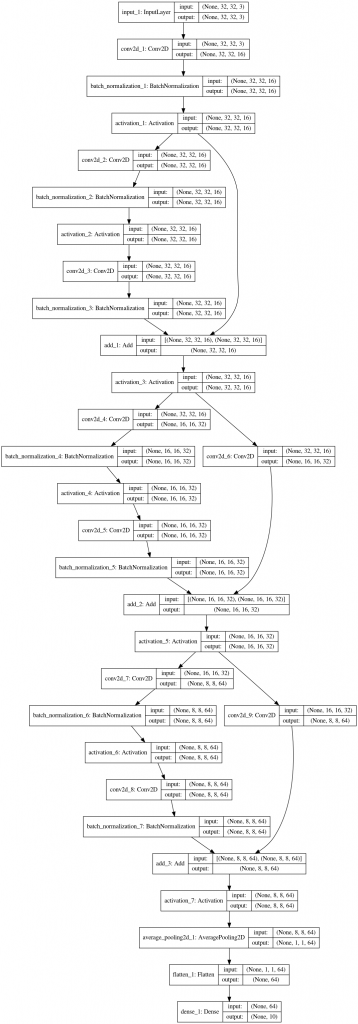
図で4者が相似かつ細部が合同なネットワークであることを確認すると、以下のようになる。
まず普通のresnet20 vs simple_conv_net20:

次にこれを圧縮して作った”resnet8-pyramid” vs simple_conv_net8:
示したいことの再確認
やや複雑になってしまったのでここで示したいことを確認しておこう。
resnet20のaccuracy – simpleconv20のaccuracy >> resnet8のaccuracy – simpleconv8のaccuracy
resnet20のaccuracy >> resnet8のaccuracy
が成り立つはずである。だって、resnetこそが150層の超ディープラーニングを可能にし、「ディープ=正義」の公式を打ち立てたのだから。
原論文の主張
ちなみに、原論文では
simpleconv54のaccuracy << simpleconv36のaccuracy
も主張されていたが、今回は試していない。
ネットワーク設計の狙い
上から(入力に近い方から)解説すると
- conv 7×7,64/1
- チャンネルを増やすために入れている
- BatchNormalization+ReLU
- 勾配を増やすために入れている
- curcuit始点
- conv 3×3, 64/1
- サイズを保つため(残差をとるので)
- BatchNormalization+ReLU
- 勾配を増やすために入れている
- conv 3×3, 64/1
- サイズを保つため(残差をとるので)
- 次元を減らしたい場合はstride/2とショートカットにconv1x1を入れる
- BatchNormalization
- ReLUが入っていないことに注意(伏線)
- curcuit終点
- Addする。conv2層で、H=F-xをゼロにすることを学習させる
- ReLU
- Addのあとにアクティベーションを入れる理由は、H=F-x=0を学習するより、ReLU(H)=0を学習するほうが容易だからである。(F-xは当然負になりうるが、不領域の値が0と全然違っても許される自由度がある。)
- ↑重要ポイントなので読み飛ばさないよう重々承知おかれたし
- pool
- AveragePoolingであり、MaxPoolingでないのは、情報量を失わなわせないためだと考えられる。
- Flatten+Dense
といったところだろうか。Dropoutは存在しない。原論文でも使っていない。
学習率の実装
resnetの学習率のスケジューラーは非自明な階段状関数が使われている。これは全く意味不明である。
SGDのmomentum=0.9でinit=0.001だが、この条件は、pyramid構造でパラメーターが削減されているときだけ動く。次元圧縮しないケース(すべてのstride=1に設定する)では、普通にlossが発散してお亡くなりになる。
このように気難しいので、論文の値にそのまま倣うしかなかった。
結果
resnet20のaccuracy – simpleconv20のaccuracy >> resnet8のaccuracy – simpleconv8のaccuracy
は、予想通り
0.9149 – 0.9052 = 0.097 >> 0.625 – 0.593 = 0.032
でした。(epoch200で比較)
依然気になる点
- resnet4は学習できなかった。
- resnet8でも、次元圧縮をしなくすると学習できなかった。
- 特に、SGDが発散するようになった。
- resnet32, 56, 152で検証していない。
次の休暇でやるかもしれない。
ソースコード
ひみちゅ。
一応参考文献(論文など)
自分で検証したい人向けとはいいつつ、そういう人は既に知っているとは思いますが…原論文へのリンク。
https://arxiv.org/abs/1512.03385
kerasのサンプルも勉強になった。このパラメーターではresnet8は学習できないが。
https://keras.io/examples/cifar10_resnet/
Good Luck。res沼を存分に楽しんでほしい。
ピンバック: 画像認識AIの発展(2011~2020) | The Big Computing
ピンバック: データサイエンス人気記事 - The Big Computing