教科書
データサイエンティストに統計検定は必須です。売上を伸ばす施策では機械学習より統計が役立つケースもあります。スキルとキャリアを考えるきっかけに。


統計検定の教科書は公式本です。これを完全理解すれば受かります。
過去問
チートシート
期待値は線型演算子
![E[aX+bY]=aE[X]+bE[Y]](http://l.wordpress.com/latex.php?latex=E%5BaX%2BbY%5D%3DaE%5BX%5D%2BbE%5BY%5D&bg=FFFFFF&fg=00000&s=0 "E[aX+bY]=aE[X]+bE[Y]")
共分散
 = a^2V(X) + 2abCov(X,Y) + b^2V(Y) \\\\ V(aX-bY) = a^2V(X) -2abCov(X,Y) + b^2V(Y) \\\\ Cov(X,Y) = \displaystyle \frac{1}{n} \sum^{n}_{i=1} (x_i - \bar{x})(y_i - \bar{y})")
共分散=Cov(X,Y)はXとYが独立な時0です。
ベイズの定理
=\displaystyle \frac{P(Y|X)P(X)}{P(Y)}")
条件付き確率においてP(Y|X)のXとYを入れ替える道具です。機械学習に必須。同時分布の定義と周辺化もおさえておく
 = P(Y|X)P(X) = P(X|Y)P(Y) \\\\ P(X) = \displaystyle\sum_{Y} P(X,Y) \\\\ = \sum_{Y} P(X|Y)P(Y)")
2次3次モーメント
モーメントは真っ向から計算していると時間が足りなくなるので、必ず公式で出す。
 = E(X^2) - E(X)^2")
確率母関数
確率母関数(G)・モーメント母関数(M)・キュミュラント母関数(K)・特性関数(S)
![G = E[t^X] \\\\ M = E[e^{tX}] \\\\ K = log(M) = log(E[e^{tX}]) \\\\ \phi = E[e^{itX}]](http://l.wordpress.com/latex.php?latex=G%20%3D%20E%5Bt%5EX%5D%20%5C%5C%5C%5C%20M%20%3D%20E%5Be%5E%7BtX%7D%5D%20%5C%5C%5C%5C%20K%20%3D%20log%28M%29%20%3D%20log%28E%5Be%5E%7BtX%7D%5D%29%20%5C%5C%5C%5C%20%5Cphi%20%3D%20E%5Be%5E%7BitX%7D%5D&bg=FFFFFF&fg=00000&s=0 "G = E[t^X] \\\\ M = E[e^{tX}] \\\\ K = log(M) = log(E[e^{tX}]) \\\\ \phi = E[e^{itX}]")
正規分布の確率母関数
 \\\\ \phi = \exp(i \mu t - \frac{\sigma^2 t^2}{2})")
確率母関数のtをitで置き換えるだけで特性関数になります。逆に正規分布はフーリエ変換で不変なので特性関数(tの正規分布)を覚え、itをtで置き換えてもOKです。
ヤコビアン
何度やっても分母と分子を逆にしたり、逆函数を忘れたりするので、覚えた方が良い。
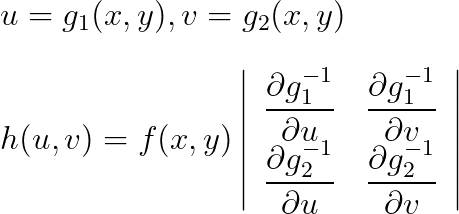
, v = g_2(x,y) \\\\ h(u,v) = f(x,y) \left \vert \displaystyle \begin{array}{rrr} \displaystyle \frac{\partial g_1^{-1}}{\partial u} & \displaystyle \frac{\partial g_1^{-1}}{\partial v} \\ \displaystyle \frac{\partial g_2^{-1}}{\partial u} & \displaystyle \frac{\partial g_2^{-1}}{\partial v} \end{array} \right \vert")
確率変数の畳み込み(足し算)
全確率の式+ヤコビアン
 = \displaystyle \int f_X(X)f_Y(Z-X) dX")
正規分布の再生性
冒頭の、期待値の線型性と、線形和に対する分散の公式を使う。
![Z = X+Y \\\\ E[Z] = E[X] + E[Y], V[Z] = V[X] + 0 + V[Y] \\\\ h(Z) = \displaystyle \frac{1}{\sqrt{2 \pi (\sigma_1^2 + \sigma_2^2)}} \exp(-\frac{(z-\mu_1-\mu_2)}{2 (\sigma_1^2 + \sigma_2^2)}) = N(\mu_1+\mu_2, \sigma_1^2 + \sigma_2^2) \\\\ \\\\ Z = X+X+... +X = nX \\\\ h(Z) = N(n\mu, n\sigma^2)](http://l.wordpress.com/latex.php?latex=Z%20%3D%20X%2BY%20%5C%5C%5C%5C%20E%5BZ%5D%20%3D%20E%5BX%5D%20%2B%20E%5BY%5D%2C%20V%5BZ%5D%20%3D%20V%5BX%5D%20%2B%200%20%2B%20V%5BY%5D%20%5C%5C%5C%5C%20h%28Z%29%20%3D%20%5Cdisplaystyle%20%5Cfrac%7B1%7D%7B%5Csqrt%7B2%20%5Cpi%20%28%5Csigma_1%5E2%20%2B%20%5Csigma_2%5E2%29%7D%7D%20%5Cexp%28-%5Cfrac%7B%28z-%5Cmu_1-%5Cmu_2%29%7D%7B2%20%28%5Csigma_1%5E2%20%2B%20%5Csigma_2%5E2%29%7D%29%20%3D%20N%28%5Cmu_1%2B%5Cmu_2%2C%20%5Csigma_1%5E2%20%2B%20%5Csigma_2%5E2%29%20%5C%5C%5C%5C%20%5C%5C%5C%5C%20Z%20%3D%20X%2BX%2B...%20%2BX%20%3D%20nX%20%5C%5C%5C%5C%20h%28Z%29%20%3D%20N%28n%5Cmu%2C%20n%5Csigma%5E2%29%20&bg=FFFFFF&fg=00000&s=0 "Z = X+Y \\\\ E[Z] = E[X] + E[Y], V[Z] = V[X] + 0 + V[Y] \\\\ h(Z) = \displaystyle \frac{1}{\sqrt{2 \pi (\sigma_1^2 + \sigma_2^2)}} \exp(-\frac{(z-\mu_1-\mu_2)}{2 (\sigma_1^2 + \sigma_2^2)}) = N(\mu_1+\mu_2, \sigma_1^2 + \sigma_2^2) \\\\ \\\\ Z = X+X+... +X = nX \\\\ h(Z) = N(n\mu, n\sigma^2)")
チェビシェフの不等式
どんな確率分布でもこの不等式を破ることはできない。
 \leq \displaystyle\frac{1}{k^2}")
大数の弱法則
チェビシェフの不等式とほぼ同じ。標本平均のnを増やすことで、分散をいくらでも小さくできる。kの置き方にコツがあるので覚える。
![\bar{X_n} = \displaystyle \frac{1}{n} \sum x_i, V[\bar{X_n}] = \frac{1}{n^2} V[X] = \frac{n \sigma^2}{n^2} = \frac{\sigma^2}{n} \\\\ k^2 V[\bar{X_n}] =\epsilon^2 \\\\ Pr(|X_n-\mu| \geq \epsilon) \leq \frac{V[\bar{X_n}]}{\epsilon^2} = \frac{\sigma^2}{\epsilon^2 n} \underset{n\to \infty}{\to} 0](http://l.wordpress.com/latex.php?latex=%5Cbar%7BX_n%7D%20%3D%20%5Cdisplaystyle%20%5Cfrac%7B1%7D%7Bn%7D%20%5Csum%20x_i%2C%20V%5B%5Cbar%7BX_n%7D%5D%20%3D%20%5Cfrac%7B1%7D%7Bn%5E2%7D%20V%5BX%5D%20%3D%20%5Cfrac%7Bn%20%5Csigma%5E2%7D%7Bn%5E2%7D%20%3D%20%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D%20%5C%5C%5C%5C%20k%5E2%20V%5B%5Cbar%7BX_n%7D%5D%20%3D%5Cepsilon%5E2%20%5C%5C%5C%5C%20Pr%28%7CX_n-%5Cmu%7C%20%5Cgeq%20%5Cepsilon%29%20%5Cleq%20%5Cfrac%7BV%5B%5Cbar%7BX_n%7D%5D%7D%7B%5Cepsilon%5E2%7D%20%3D%20%5Cfrac%7B%5Csigma%5E2%7D%7B%5Cepsilon%5E2%20n%7D%20%5Cunderset%7Bn%5Cto%20%5Cinfty%7D%7B%5Cto%7D%200&bg=FFFFFF&fg=00000&s=0 "\bar{X_n} = \displaystyle \frac{1}{n} \sum x_i, V[\bar{X_n}] = \frac{1}{n^2} V[X] = \frac{n \sigma^2}{n^2} = \frac{\sigma^2}{n} \\\\ k^2 V[\bar{X_n}] =\epsilon^2 \\\\ Pr(|X_n-\mu| \geq \epsilon) \leq \frac{V[\bar{X_n}]}{\epsilon^2} = \frac{\sigma^2}{\epsilon^2 n} \underset{n\to \infty}{\to} 0")
二項分布
(k)= {}_n \mathrm{C} _k p^k (1-p)^{n-k}")
ポアソン分布
e^(-λ)は正規化定数。
=\displaystyle\frac{\lambda^k}{k!}e^{-\lambda} \\\\ e^{\lambda} = \sum_{k=0}^{\infty} \frac{\lambda^k}{k!}")
超幾何分布
(k)=\displaystyle\frac{ {}_K \mathrm{C} _k \cdot {}_{N-K} \mathrm{C} _{n-k}}{ {}_N \mathrm{C} _n }")
ガンマ分布
(x)=\displaystyle\frac{1}{\Gamma(k)} x^{k-1} \theta^{-k} e^{-\frac{x}{\theta}}")
負の二項分布
ガンマ分布の重要な応用先として(ガンマ分布を使って負の二項分布を求める方法は別途記事書きます)。実務でよく出る。「コイン投げでr回の表を得るのに必要な試行回数」の分布なので、r<k<∞。この定義だと、k回目が必ず表なので、k-1回のうちr-1回を表にする場合の数が出てくる。
(k)={}_{k-1} \mathrm{C} _{r-1} p^r (1-p)^{k-r}")
パスカル分布・ポリア分布もこの一種として説明がつく。
ベータ分布
ベイズ推定で最初に使う確率分布。0<x<1の区間の曲線。
 = \displaystyle\frac{1}{B(\alpha, \beta)} x^{\alpha -1} (1-x)^{\beta - 1}")
検定で使う分布 – χ(chi/カイ)2乗分布・t分布・F分布
 \\\\ Z=\displaystyle\sum^k X^2 \\\\ Z \sim \chi^2(k)")
これを自由度kのカイ2乗分布といいます。自由度が1のとき、正規分布を温度で微分したものを使って計算できます。自由度2以上の場合に対しても、同様に計算できます。この結果、
 = \displaystyle\frac{1}{2^{k/2} \Gamma(k/2)} x^{k/2 - 1}\exp(-\frac{x}{2})")
余談ですが、最初見た時”chi”を”ち”だと思っていました。
さて、カイ2乗分布(自由度1)を見ると、0.5+nに対するガンマ関数の値を覚えておいた方がいいことがわかります。この関数は統計物理学で、高次元球体積として頻出します。
=\sqrt{\pi} \\\\ \Gamma(0.5+1)=\displaystyle\frac{1}{2}\sqrt{\pi}\\\\ \Gamma(0.5+2)=\displaystyle\frac{1 \cdot 3}{2^2}\sqrt{\pi}")
不偏分散と不偏性・一致性
白色化
")
十分統計量
順序統計量
どんな確率分布に対しても計算できる万能関数です。ノンパラメトリック検定を見てください。
最小分散不偏推定量(MVUE・UMVUE)
有効推定量
AIC(赤池情報量基準)
エントロピー
機械学習の最重要概念です。暗記必須。logの底は2でとるイメージがありますが、他の底でも定数倍しか変わりません。
 = - \displaystyle\int P(x) \log P(x) dx")
例) 確率1/2のコイン投げのエントロピーは2。1bitとも言います。
カルバック・ライブラー・ダイバージェンス
KLDともいいます。確率分布を推定する問題では真の分布をQで表すことが多く、「PがQからどれだけ離れているか」を表します。「QがPからどれだけ離れているか」ではありません(KLDの非対称性)。
![D_{KL}(P || Q)=\displaystyle\int P(x) \log \displaystyle\frac{P(x)}{Q(x)} dx = E_P[\log P - \log Q] = H(P, Q) - H(X) \\\\ H(P, Q) = - E_P[\log Q]](http://l.wordpress.com/latex.php?latex=D_%7BKL%7D%28P%20%7C%7C%20Q%29%3D%5Cdisplaystyle%5Cint%20P%28x%29%20%5Clog%20%5Cdisplaystyle%5Cfrac%7BP%28x%29%7D%7BQ%28x%29%7D%20dx%20%3D%20E_P%5B%5Clog%20P%20-%20%5Clog%20Q%5D%20%3D%20H%28P%2C%20Q%29%20-%20H%28X%29%20%5C%5C%5C%5C%20H%28P%2C%20Q%29%20%3D%20-%20E_P%5B%5Clog%20Q%5D&bg=FFFFFF&fg=00000&s=0 "D_{KL}(P || Q)=\displaystyle\int P(x) \log \displaystyle\frac{P(x)}{Q(x)} dx = E_P[\log P - \log Q] = H(P, Q) - H(X) \\\\ H(P, Q) = - E_P[\log Q]")
KLDは相対エントロピーとも言います。H(P,Q)は交差エントロピーとも言います。
相互情報量
相対エントロピーと紛らわしいですが、XとYの関係が独立性からどれだけ離れているかを意味します。独立な時、相互情報量は0です。
 = D_{KL}(P(X,Y) || P(X)P(Y))")
デルタ法
確率変数Xの関数f(X)はまた確率変数になります。期待値と分散を、微分可能なfについて近似する式です。
![E[f(X)]=f(\mu)\\\\ V[f(X)]=f](http://l.wordpress.com/latex.php?latex=E%5Bf%28X%29%5D%3Df%28%5Cmu%29%5C%5C%5C%5C%20V%5Bf%28X%29%5D%3Df%27%28%5Cmu%29%5E2%20V%5BX%5D&bg=FFFFFF&fg=00000&s=0 "E[f(X)]=f(\mu)\\\\ V[f(X)]=f")
統計的仮説検定
ネイマン・ピアソンの定理
理解度チェックリスト
もちろん上の式は全部覚えておきたいですが、それだけでは全てをカバーできていません。公式テキストの「理解度チェックリスト」を作りました。チェックは自動保存され、次回再ロードします。自分がそのうち何割を理解しているのかを記録することが出来ます。
統計検定1級の場合、5問から3問を選んで解きます。難しい問題を避けることもあるので、5問中4問は専門分野として持っておきたいところです。そのため、このチェックリストで80%以上取りましょう。
今の理解度・・・%
- 独立性
- 条件付き確率とベイズの定理
- 確率変数の分布関数と確率密度関数の相互変換
- 同時分布からの周辺分布と条件付き確率密度関数の導出
- 確率母関数・モーメント母関数・キュミュラント母関数・特性関数
- モーメントの導出
- パーセント点の算出
- 変数変換後の確率密度関数の導出
- 確率変数の線型結合
- 確率密度関数の導出
- 再生性
- 大数の弱法則の証明
- 中心極限定理の証明
- 二項分布の正規近似
- 二項分布のポアソン近似
- 超幾何分布の二項分布近似
- 多項分布の周辺化による二項分布の導出
- ガンマ分布とベータ分布の関係
- ガンマ分布と負の二項分布の関係
- 多変量正規分布の性質
- 危険率
- カイ二乗分布の導出
- t分布(スチューデント分布)の導出
- F分布(フィッシャー分布)の導出
- 正規分布からの無作為標本
- 標本平均の分布
- 不偏分散の分布
- 標本平均を√不偏分散で割った値の分布
- 十分統計量
- 順序統計量
- 最尤推定法
- モーメント法
- 漸近正規性
- 漸近有効性
- 不偏性
- 一致性
- 最小二乗推定量
- 最小分散不変推定量
- 有効推定量
- 相対効率
- 赤池情報量基準(AIC)
- カルバック・ライブラダイバージェンスからのAICの導出
- モデル選択
- デルタ法
- 区間推定
- 信頼区間
- 回帰
過去問
過去問は公式の過去問を使います。試験は90分です。
2014年過去問
http://www.toukei-kentei.jp/about/pastpaper/2014n/2014n_grade1.pdf
実戦
実戦だと、知識があるだけだと戦えなかったりします。知識を補う「何か」が必要なのかもしれません。この本とかいいと思います。

ピンバック: ノンパラメトリック検定まとめ – The Big Computing
ピンバック: 正規分布の3次モーメントの楽な計算法(確率論の裏ワザ) – The Big Computing
ピンバック: 学問のWebサイトでSEOをするということ – The Big Computing
ピンバック: スパイラル・ラーニング 技術者の四季と螺旋 | The Big Computing
ピンバック: データサイエンス人気記事 - The Big Computing